什么是图
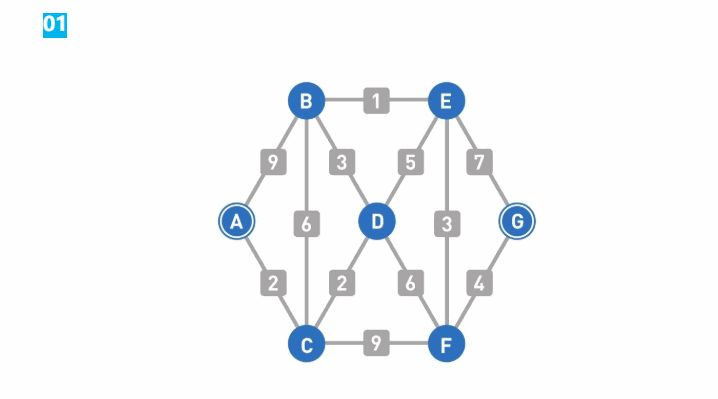
图由顶点和连接每对顶点的边所构成的图形就是图,图表现各种关系。
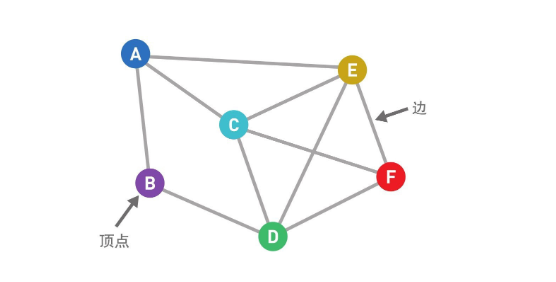
加权图给边加上一个值,这个值叫作边的"权重"或者"权"。加了权的图叫作"加权图"。没有权的边只能表示两个顶点的连接状态,而有权的边就可以表示顶点之间的"连接程度"。
有向图当我们想在路线图中表示该路线只能单向行驶时,就可以给边加上箭头,而这样的图就叫作"有向图"。比如网页的链接是有方向性的,用有向图来表示会很方便。边上没有箭头的图是"无向图"。
广度优先搜索
广度优先搜索是一种对图进行搜索的算法。假设我们一开始位于某个顶点(即起点),此时并不知道图的整体结构,而我们的目的是从起点开始顺着边搜索,直到到达指定顶点(终点).在此过程中每走到一个顶点,就会判断一次它是否为终点。广度优先搜索会优先从离起点近的的顶点开始搜索。
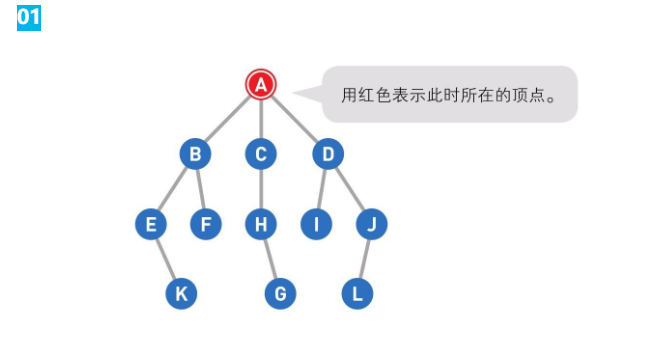
G为终点将A可以直达的三个顶点B,C,D设为下一步的候补顶点。从候补顶点中选出一个顶点。优先选择最早成为候补的那个顶点(候补顶点是用"先入先出"的方式来管理的,因此可以使用"队列"这个数据结构。),如果多个顶点同时成为候补,随机选择其中一个。
 接下来将B直达的两个顶点E和F设为候补顶点。此时,最早成为候补顶点的是C和D,我们选择了左边的顶点C。移动到选中的顶点C上,将C直达的顶点H设为候补顶点。重复上述操作直到到达终点,或者所有的顶点都被遍历为止。这个示例中的搜索顺序为A、B、C、D、E、F、H、I、J、K。完成了从A到I的搜索,现在在顶点J处。到达终点G,搜索结束。
接下来将B直达的两个顶点E和F设为候补顶点。此时,最早成为候补顶点的是C和D,我们选择了左边的顶点C。移动到选中的顶点C上,将C直达的顶点H设为候补顶点。重复上述操作直到到达终点,或者所有的顶点都被遍历为止。这个示例中的搜索顺序为A、B、C、D、E、F、H、I、J、K。完成了从A到I的搜索,现在在顶点J处。到达终点G,搜索结束。
补充为了方便说明,上面用的是没有闭环的图(树)。
深度优先搜索
深度优先搜索会沿着一条路径不断往下搜索直到不能再继续为止,然后再折返,开始搜索下一条候补路径。
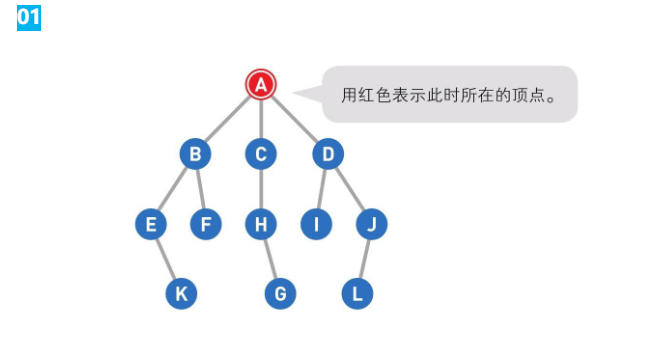
A为起点,G为终点。一开始我们在起点A上。将可以从A直达的三个顶点B、C、D设为下一步的候补点。从候补点中选出一个顶点。优先选择最新成为候补的点(此处候补顶点是用"后入先出"的方式来管理的,因此我们可以用栈这个数据结构),如果几个顶点同时成为候补,那我们可以从中随意选择一个B。移动到选中的顶点B,此时我们在B上,将可以从B直达的两个顶点E和F设为候补顶点。我们选择左边的顶点E,移动到选中的顶点E上,将E直达的顶点K设为候补顶点。重复上述操作直到到达终点,或者所有顶点都被遍历为止。这个示例的搜索顺序为A、B、E、K、F、C、H。
差异广度优先搜索选择的是最早成为候补的顶点,因为顶点离起点越近就越早成为候补,所以会从离起点近的地方开始按顺序搜索;而深度优先搜索选择的则是最新成为候补的顶点,所以会一路往下,沿着新发现的路径不断深入搜索。
贝尔曼-福特算法
贝尔曼-福特算法的名称取自其创始人理查德·贝尔曼和莱斯特·福特的名字。贝尔曼也因为提出了该算法中的一个重要分类“动态规划”而被世人所熟知。
贝尔曼-福特算法是一种在图中求解最短路径问题的算法。最短路径问题就是在加权图指定了起点和终点的前提下,寻找从起点到终点的路径中权重总和最小的那条路径。
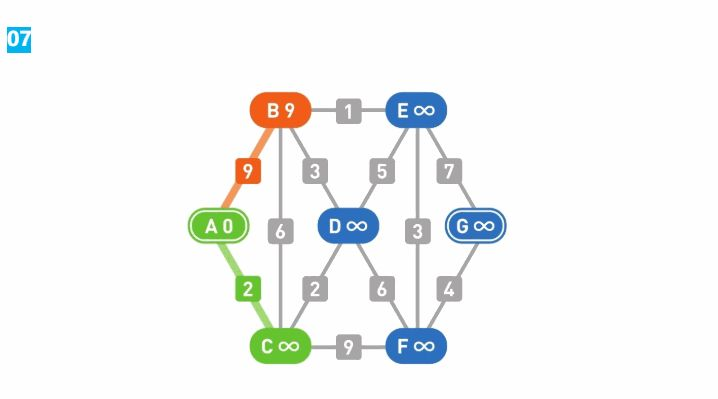
A-->G首先设置各个顶点的初始权重:起点为0,其他顶点为无穷大(∞)。这个权重表示的是从A到该顶点的最短路径的的暂定距离。随着计算往下进行,这个值会变得越来越小,最终收敛到正确的数值。
从所有的边中选出一条边,此处选择了连接A-B的边。然后,分别计算这条边从一端到另一端的权重,计算方法是“顶点原本的权重+边的权重”。只要按顺序分别计算两个方向的权重即可,从哪一端开始都没有问题。此处我们选择按顶点权重从小到大的方向开始计算。
A的权重小于B,因此先计算从A到B的权重。A的权重是0,边A-B的权重是9,因此A到B的权重是0+9=9。
如果计算结果小于顶点的值,就更新这个值。顶点B的权重是无穷大,比9大,所以把它更新为9。更新时需要记录计算的是从哪个顶点到该顶点的路径。
接下来计算从B到A的权重。B的权重为9,从B到A的权重便为9+9=18。与顶点A现在的值0进行比较,因为现在的值更小,所以不更新。
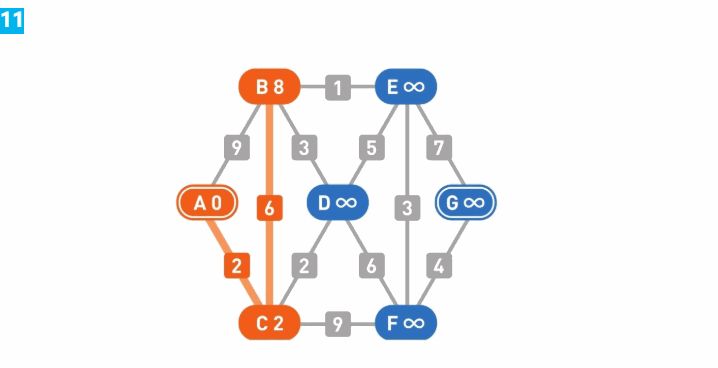
 对所有的边都执行同样的操作。在执行顺序上没有特定要求,此处我们选择从靠近左侧的边开始计算。先选出一条边数值更新了,顶点C的权重变成了2。同样地,再选出一条边权重又更新了。此时就能看出,从顶点A前往顶点B时,比起从A直达B,在C中转一次的权重更小。接着对所有的边进行更新操作。
对所有的边都执行同样的操作。在执行顺序上没有特定要求,此处我们选择从靠近左侧的边开始计算。先选出一条边数值更新了,顶点C的权重变成了2。同样地,再选出一条边权重又更新了。此时就能看出,从顶点A前往顶点B时,比起从A直达B,在C中转一次的权重更小。接着对所有的边进行更新操作。
更新边B-D和边B-E。
 更新边C-D和边C-F。
更新边C-D和边C-F。
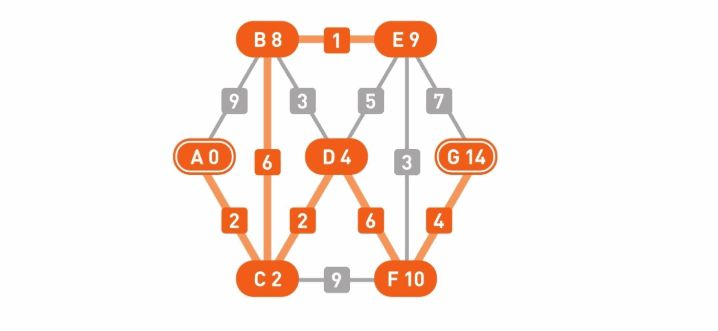 更新完所有的边后,第1轮更新就结束了。接着,重复对所有边的更新操作,直到权重不能被更新为止。
更新完所有的边后,第1轮更新就结束了。接着,重复对所有边的更新操作,直到权重不能被更新为止。
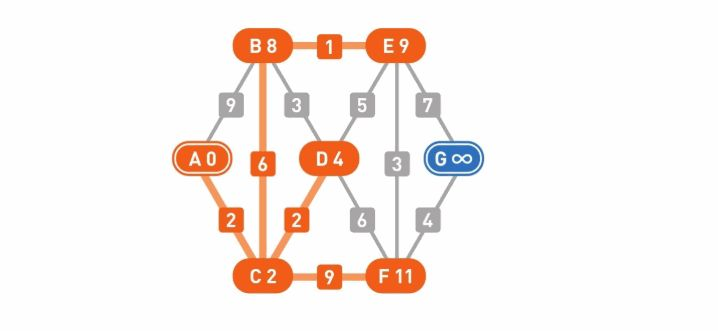
第2轮更新也结束了。顶点B的权重从8变成了7,顶点E的权重从9变成了8。接着,再执行一次更新操作。
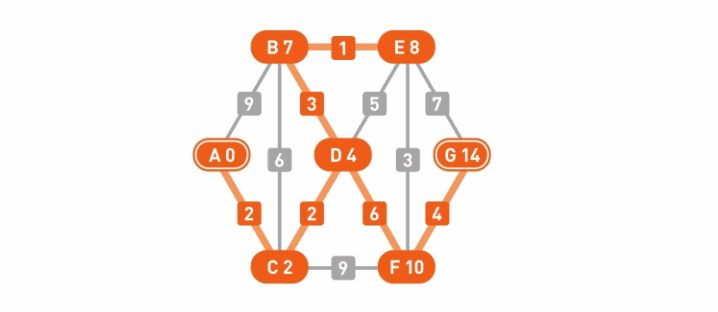
第3轮更新结束,所有顶点的权重都不再更新,操作到此为止。算法的搜索流程也就此结束,我们找到了从起点到其余各个顶点的最短路径。
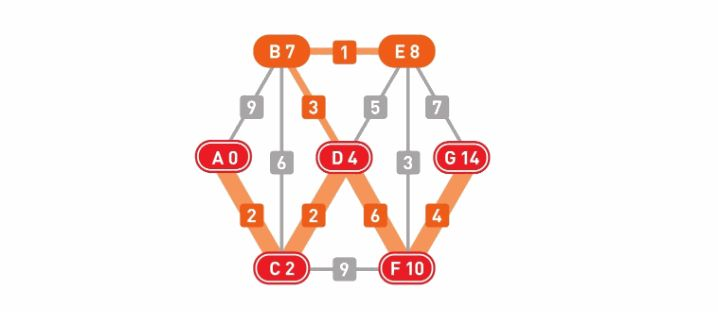 根据搜索结果可知,从起点A到终点G的最短路径是A-C-D-F-G,权重为14。
根据搜索结果可知,从起点A到终点G的最短路径是A-C-D-F-G,权重为14。
时间复杂度将图的顶点数设为n、边数设为m,我们来思考一下贝尔曼-福特算法的时间复杂度是多少。该算法经过n轮更新操作后就会停止,而在每轮更新操作中都需要对各个边进行1次确认,因此1轮更新所花费的时间就是O(m),整体的时间复杂度就是O(nm)。
狄克斯特拉算法
狄克斯特拉算法(Dijkstra) 与上面文章中的贝尔曼-福特算法类似。
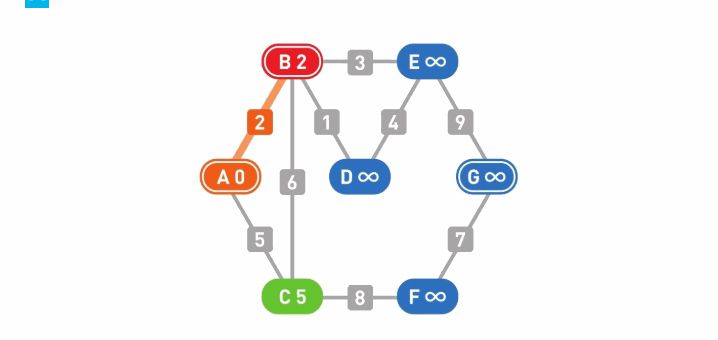
A-->G首先设置各个顶点的初始权重:起点为0,其他顶点勿穷大(∞)。从A出发寻找可以从目前所在的顶点直达且尚未被搜索过的顶点,此处为顶点B和顶点C,将它们设为下一步的候补顶点。
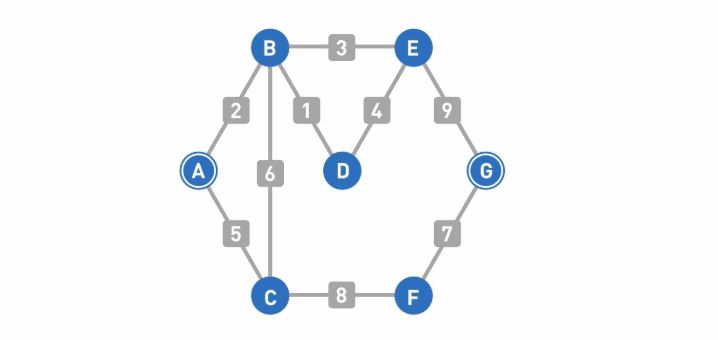 计算各个候补顶点的权重。计算方法是“目前所在顶点的权重+目前所在顶点到候补顶点的权重”。比如起点A的权重是0,那么顶点B的权重就是0+2=2。用同样的方法计算顶点C,结果就是0+5=5。
计算各个候补顶点的权重。计算方法是“目前所在顶点的权重+目前所在顶点到候补顶点的权重”。比如起点A的权重是0,那么顶点B的权重就是0+2=2。用同样的方法计算顶点C,结果就是0+5=5。

如果计算结果小于候补顶点的值,就更新这个值。顶点B和顶点C现在的权重都是无穷大,大于计算结果,所以更新这两个顶点的值。
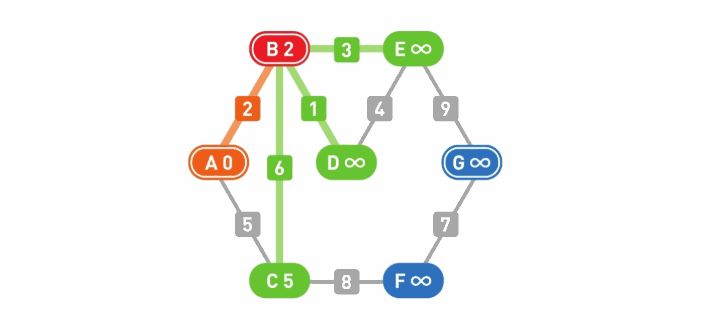
从候补顶点中选出权重最小的顶点。此处B的权重最小,那么路径A-B就是从起点A到顶点B的最短路径。因为如果要走别的路径,那么必定会经过顶点C,其权重也就必定会高于A-B这条路径。确定了最短路径,移动到顶点B。
 将可以从顶点B直达的顶点设为新的候补顶点,于是顶点D和顶点E也成为了候补。目前有三个候补顶点C、D、E。
将可以从顶点B直达的顶点设为新的候补顶点,于是顶点D和顶点E也成为了候补。目前有三个候补顶点C、D、E。
 用相同的方法计算各个候补顶点的权重。从B到C的权重为2+6=8,比C当前的权重5大,因此不更新这个值。更新了剩下的顶点D和E。
用相同的方法计算各个候补顶点的权重。从B到C的权重为2+6=8,比C当前的权重5大,因此不更新这个值。更新了剩下的顶点D和E。
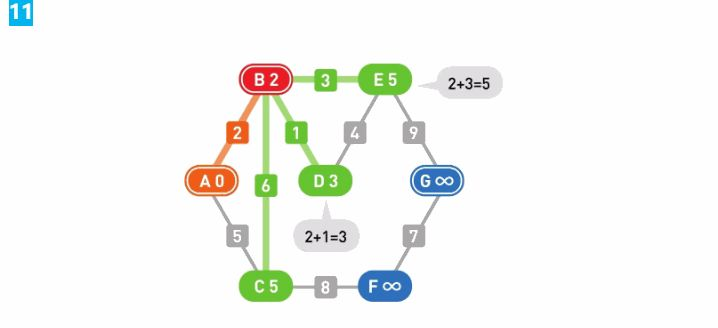 从候补顶点中选出权重最小的顶点。此处D的权重最小,那么路径A-B-D就是从起点A到顶点D的最短路径。A-B-D这条路径是通过逐步从候补顶点中选择权重最小的顶点来得到的,所以如果经过其他顶点到达D,其权重必定会大于这条路径。
从候补顶点中选出权重最小的顶点。此处D的权重最小,那么路径A-B-D就是从起点A到顶点D的最短路径。A-B-D这条路径是通过逐步从候补顶点中选择权重最小的顶点来得到的,所以如果经过其他顶点到达D,其权重必定会大于这条路径。
要重复执行同样的操作直到到达终点G为止。移动到顶点D后算出了E的权重,然而并不需要更新它(因为3+4=7)。现在,两个候补顶点C和E的权重都为5,所以选择哪一个都可以。此处我们选择了C,于是起点A到顶点C的最短路径便确定了。
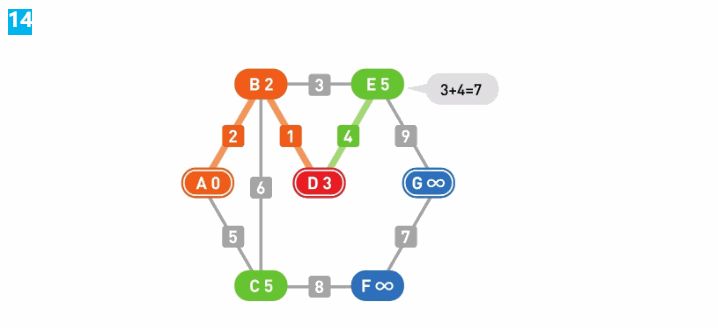
移动到C后,顶点F成为了新的候补顶点,且F的权重被更新为13。此时的候补顶点中,E为5、F为13,所以我们选择了权重更小的E,起点A到顶点E的最短路径也就确定了下来。
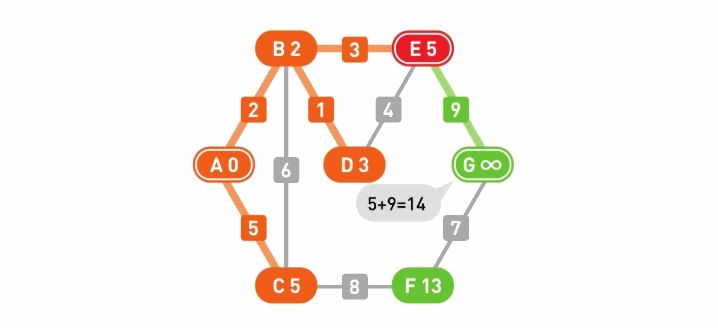 移动到F。顶点G的权重计算结果为13+7=20,比现在的值14要大,因此不更新它。由于候补顶点只剩G了,所以选择G,并确定了起点A到顶点G的最短路径。到达终点G,搜索结束。
移动到F。顶点G的权重计算结果为13+7=20,比现在的值14要大,因此不更新它。由于候补顶点只剩G了,所以选择G,并确定了起点A到顶点G的最短路径。到达终点G,搜索结束。
解说比起需要对所有的边都重复计算权重和更新权重的贝尔曼-福特算法,狄克斯特拉算法多了一步选择顶点的操作,这使得它在求最短路径上更为高效。将图的顶点数设为n、边数设为m,那么如果事先不进行任何处理,该算法的时间复杂度就是O(n2)。不过,如果对数据结构进行优化,那么时间复杂度就会变为O(m+nlogn)。
A*算法
A-Star算法由狄克斯特拉算法发展而来。狄克斯特拉算法会从离起点近的顶点开始,按顺序求出起点到各个顶点的最短路径。也就是说,一些离终点较远的顶点的最短路径也会被计算出来,但这部分其实是无用的。与之不同,A* 就会预先估算一个值,并利用这个值来省去一些无用的计算。
A-Star暂时还未理解步骤,待更新这部分内容。游戏中会用到,但消耗很大计算资源,需要和其他算法配合使用
