Redis中的缓存穿透、雪崩、击穿的原因以及解决方案(详解)
概述
① 缓存穿透:大量请求根本不存在的key(下文详解)
② 缓存雪崩:redis中大量key集体过期(下文详解)
③ 缓存击穿:redis中一个热点key过期(大量用户访问该热点key,但是热点key过期)
穿透解决方案:
对空值进行缓存
设置白名单
使用布隆过滤器
网警
雪崩解决方案:
进行预先的热门词汇的设置,进行key时长的调整
实时调整,监控哪些数据是热门数据,实时的调整key的过期时长
使用锁机制
击穿解决方案:
进行预先的热门词汇的设置,进行key时长的调整
实时调整,监控哪些数据是热门数据,实时的调整key的过期时长
使用锁机制
下文进行详解
三者出现的根本原因:
Redis命中率下降,请求直接打在DB上
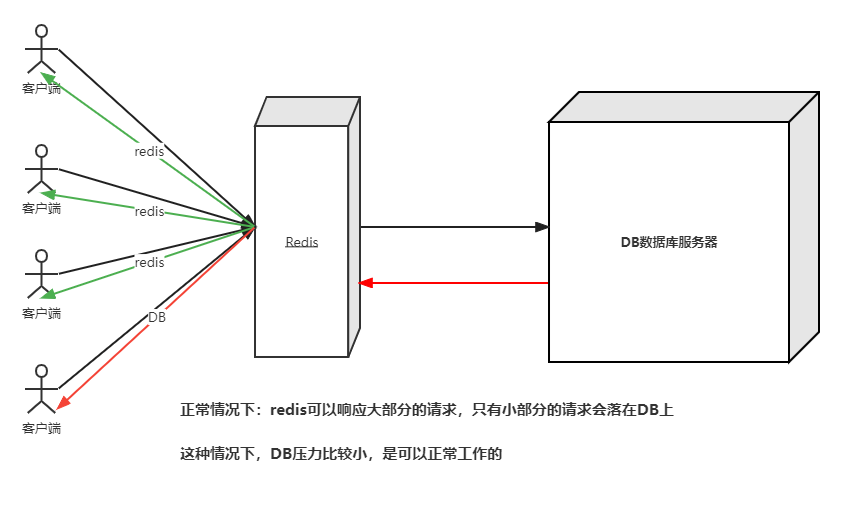
正常情况下,大量的资源请求都会被redis响应,在redis得不到响应的小部分请求才会去请求DB,这样DB的压力是非常小的,是可以正常工作的(如下图)
如果大量的请求在redis上得不到响应,那么就会导致这些请求会直接去访问DB,导致DB的压力瞬间变大而卡死或者宕机。如下图:
① 大量的高并发的请求打在redis上
② 这些请求发现redis上并没有需要请求的资源,redis命中率降低
③ 因此这些大量的高并发请求转向DB(数据库服务器)请求对应的资源
④ DB压力瞬间增大,直接将DB打垮,进而引发一系列“灾害”
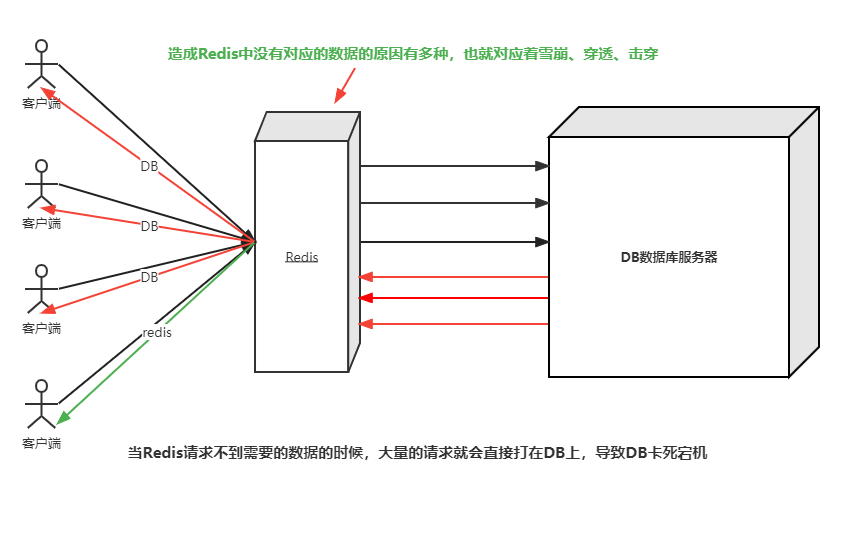
那么为什么redis会没有需要访问的数据呢?通过分析大致可以总结为三种情况,也就对应着redis的雪崩、穿透和击穿(下文开始进行详解)

情景分析 (详解)
缓存穿透
缓存穿透产生的原因:请求根本不存在的资源(DB本身就不存在,Redis更是不存在)
举例(情景在线):客户端发送大量的不可响应的请求(如下图)

当大量的客户端发出类似于:http://localhost:8080/user/19833?id=-3872 的请求,就可能导致出现缓存穿透的情况。因为数据库DB中本身就没有id=-3872的用户的数据,所以Redis也没有对应的数据,那么这些请求在redis就得不到响应,就会直接打在DB上,导致DB压力过大而卡死情景在线或宕机。
缓存穿透很有可能是黑客攻击所为,黑客通过发送大量的高并发的无法响应的请求给服务器,由于请求的资源根本就不存在,DB就很容易被打垮了。
解决方式:
对空值进行缓存:
类似于上面的例子,虽然数据库中没有id=-3872的用户的数据,但是在redis中对他进行缓存(key=-3872,value=null),这样当请求到达redis的时候就会直接返回一个null的值给客户端,避免了大量无法访问的数据直接打在DB上
实时监控:
对redis进行实时监控,当发现redis中的命中率下降的时候进行原因的排查,配合运维人员对访问对象和访问数据进行分析查询,从而进行黑名单的设置限制服务(拒绝黑客攻击)
使用布隆过滤器
使用BitMap作为布隆过滤器,将目前所有可以访问到的资源通过简单的映射关系放入到布隆过滤器中(哈希计算),当一个请求来临的时候先进行布隆过滤器的判断,如果有那么才进行放行,否则就直接拦截。
接口校验
类似于用户权限的拦截,对于id=-3872这些无效访问就直接拦截,不允许这些请求到达Redis、DB上。
注意事项:
使用空值作为缓存的时候,key设置的过期时间不能太长,防止占用太多redis资源
使用空值作为缓存只能防止黑客重复使用相同的id暴力攻击,但是如果黑客使用动态的无效id攻击就没有效果(需要配合网警)
使用布隆过滤器也是有哈希冲突的可能
缓存雪崩
缓存雪崩产生的原因:redis中大量的key集体过期
举例:
当redis中的大量key集体过期,可以理解为redis中的大部分数据都被清空了(失效了),那么这时候如果有大量并发的请求来到,那么redis就无法进行有效的响应(命中率急剧下降),请求就都打到DB上了,到时DB直接崩溃
解决方式:
将失效时间分散开
通过使用自动生成随机数使得key的过期时间是随机的,防止集体过期
使用多级架构
使用nginx缓存+redis缓存+其他缓存,不同层使用不同的缓存,可靠性更强
设置缓存标记
记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去跟新实际的key
使用锁或者队列的方式
如果查不到就加上排它锁,其他请求只能进行等待
缓存击穿
产生缓存雪崩的原因:redis中的某个热点key过期,但是此时有大量的用户访问该过期key
举例:
类似于“某男明星塌房事件”上了热搜,这时候大量的“粉丝”都在访问该热点事件,但是可能优于某种原因,redis的这个热点key过期了,那么这时候大量高并发对于该key的请求就得不到redis的响应,那么就会将请求直接打在DB服务器上,导致整个DB瘫痪。
解决方案:
提前对热点数据进行设置
类似于新闻、某博等软件都需要对热点数据进行预先设置在redis中
监控数据,适时调整
监控哪些数据是热门数据,实时的调整key的过期时长
使用锁机制
最后的防线,当热点key过期,那么就使用锁机制防止大量的请求直接打在DB
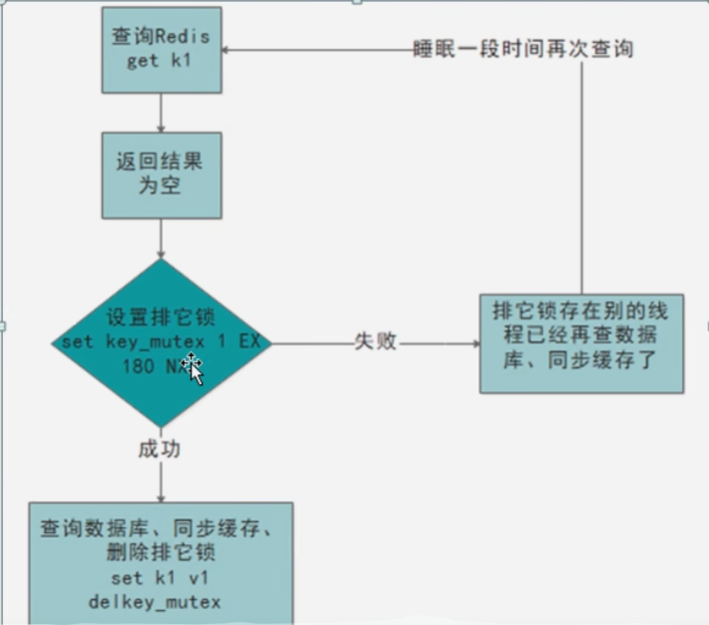
使用锁:即在查询失败的时候设置一个排它锁,并开启一个线程查询数据库并同步缓存,查询过程中不允许其他线程查询数据库,查询成功后则删除排它锁。
接口限流算法:漏桶算法&令牌桶算法&redis限流
高并发的系统通常有三把利器:缓存、降级和限流。
缓存:缓存是提高系统访问速度,缓解CPU处理压力的关键,同时可以提高系统的处理容量。
降级:降级是在突然的压力剧增的情况,根据业务以及流量对一些服务和页面的策略降级,以此释放服务器资源。
限流:限流是对于并发访问/请求进行限速,或者一个时间窗口内限速保护系统,一旦到达限制速度可以拒绝服务、排队或者等待。
限流算法
令牌桶和和漏桶,比如Google的Guava的RateLimiter进行令牌痛控制。
漏桶算法
漏桶算法是把流量比作水,水先放在桶里面并且以限定的速度出水,水过多会直接溢出,就会拒绝服务。
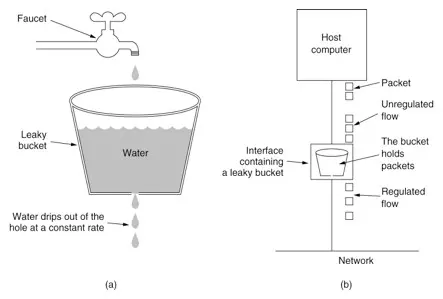
漏洞存在出水口、进水口,出水口以一定速率出水,并且有最大出水率。
在漏斗没有水的时候:
进水的速率小于等于最大出水率,那么出水速率等于进水速率,此时不会积水。
如果进水速率大于最大出水速率,那么,漏斗以最大速率出水,此时,多余的水会积在漏斗中。
如果漏斗有水的时候:
出水为最大速率。
如果漏斗未满并且有进水,那么这些水会积在漏斗。
如果漏斗已满并且有进水,那么水会溢出到漏斗外。
public class LeakyBucket {
public long timeStamp = System.currentTimeMillis(); // 当前时间
public long capacity; // 桶的容量
public long rate; // 水漏出的速度
public long water; // 当前水量(当前累积请求数)
public boolean grant() {
long now = System.currentTimeMillis();
// 先执行漏水,计算剩余水量
water = Math.max(0, water - (now - timeStamp) * rate);
timeStamp = now;
if ((water + 1) < capacity) {
// 尝试加水,并且水还未满
water += 1;
return true;
} else {
// 水满,拒绝加水
return false;
}
}
}说明:
(1)未满加水:通过代码 water +=1进行不停加水的动作。
(2)漏水:通过时间差来计算漏水量。
(3)剩余水量:总水量-漏水量。
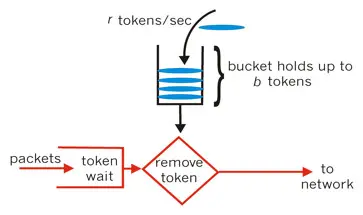
令牌桶算法
对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这个时候使用令牌桶算法比较合适。
令牌桶算法以恒定的速率产生令牌,之后再把令牌放回到桶当中,令牌桶有一个容量,当令牌桶满了的时候,再向其中放令牌会被直接丢弃,
RateLimiter 用法
首先添加Maven依赖:
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>acquire(int permits)函数主要用于获取 permits 个令牌,并计算需要等待多长时间,进而挂起等待,并将该值返回。
import com.google.common.util.concurrent.ListeningExecutorService;
import com.google.common.util.concurrent.MoreExecutors;
import com.google.common.util.concurrent.RateLimiter;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.Executors;
public class Test {
public static void main(String[] args) {
ListeningExecutorService executorService = MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(100));
// 指定每秒放1个令牌
RateLimiter limiter = RateLimiter.create(1);
for (int i = 1; i < 50; i++) {
// 请求RateLimiter, 超过permits会被阻塞
//acquire(int permits)函数主要用于获取permits个令牌,并计算需要等待多长时间,进而挂起等待,并将该值返回
Double acquire = null;
if (i == 1) {
// `acquire 1` 时,并没有任何等待 0.0 秒 直接预消费了1个令牌
acquire = limiter.acquire(1);
} else if (i == 2) {
// acquire 10时,由于之前预消费了 1 个令牌,故而等待了1秒,之后又预消费了10个令牌
acquire = limiter.acquire(10);
} else if (i == 3) {
// acquire 2 时,由于之前预消费了 10 个令牌,故而等待了10秒,之后又预消费了2个令牌
acquire = limiter.acquire(2);
} else if (i == 4) {
//`acquire 20` 时,由于之前预消费了 2 个令牌,故而等待了2秒,之后又预消费了20个令牌
acquire = limiter.acquire(20);
} else {
// `acquire 2` 时,由于之前预消费了 2 个令牌,故而等待了2秒,之后又预消费了2个令牌
acquire = limiter.acquire(2);
}
executorService.submit(
new Task("获取令牌成功,获取耗:" + acquire + " 第 " + i + " 个任务执行"));
}
}
}
class Task implements Runnable {
String str;
public Task(String str) {
this.str = str;
}
@Override public void run() {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); System.out.println(sdf.format(new Date()) + " | " + Thread.currentThread().getName() + str);
}
}一个RateLimiter主要定义了发放permits的速率。如果没有额外的配置,permits将以固定的速度分配,单位是每秒多少permits。默认情况下,Permits将会被稳定的平缓的发放。
RateLimiter 的执行结果如下
2023-01-03 06:18:53.684 | pool-1-thread-1获取令牌成功,获取耗:0.0 第 1 个任务执行2023-01-03 06:18:54.653 | pool-1-thread-2获取令牌成功,获取耗:0.985086 第 2 个任务执行2023-01-03 06:19:04.640 | pool-1-thread-3获取令牌成功,获取耗:9.986942 第 3 个任务执行2023-01-03 06:19:06.643 | pool-1-thread-4获取令牌成功,获取耗:2.000365 第 4 个任务执行2023-01-03 06:19:26.641 | pool-1-thread-5获取令牌成功,获取耗:19.99702 第 5 个任务执行2023-01-03 06:19:28.640 | pool-1-thread-6获取令牌成功,获取耗:1.999456 第 6 个任务执行2023-01-03 06:19:30.651 | pool-1-thread-7获取令牌成功,获取耗:2.000317 第 7 个任务执行2023-01-03 06:19:32.640 | pool-1-thread-8获取令牌成功,获取耗:1.988647 第 8 个任务执行从上面的结果可以知道,令牌桶具备预消费能力。
`acquire 1` 时,并没有任何等待 0.0 秒 直接预消费了1个令牌
`acquire 10`时,由于之前预消费了 1 个令牌,故而等待了1秒,之后又预消费了10个令牌
`acquire 2` 时,由于之前预消费了 10 个令牌,故而等待了10秒,之后又预消费了2个令牌
`acquire 20` 时,由于之前预消费了 2 个令牌,故而等待了2秒,之后又预消费了20个令牌
`acquire 2` 时,由于之前预消费了 20 个令牌,故而等待了20秒,之后又预消费了2个令牌
`acquire 2` 时,由于之前预消费了 2 个令牌,故而等待了2秒,之后又预消费了2个令牌
`acquire 2` 时 .....预消费能力是一个类似前人挖坑,后人填坑的过程,从上面的运行结果来看,如果上一次请求获取的permit数越多,那么下一次再获取授权时更待的时候会更长,反之,如果上一次获取的少,那么时间向后推移的就少,下一次获得许可的时间更短。
Redis 限流
基于Redis的setnx的操作
限流的主要目的就是为了在单位时间内,有且仅有N数量的请求能够访问我的代码程序,依靠setnx 可以轻松完成CAS操作,同时被获取的相同Key设置过期时间(expire),比如10秒内限定20个请求,那么我们在setnx的时候可以设置过期时间10,当请求的setnx数量达到20时候即达到了限流效果。
setnx的操作的弊端是无法进行限流统计,如果需要统计10秒内获取了多少个“桶”,需要在统计的过程中所有的桶都被持有。
基于Redis的数据结构zset
限流涉及的最主要的就是滑动窗口,上面也提到1-10怎么变成2-11。其实也就是起始值和末端值都各+1即可。
zset数组可以实现类似滑动数组的方式,每次请求进入的时候,可以生成唯一的UUID作为value,score可以用当前时间戳表示,因为score我们可以用来计算当前时间戳之内有多少的请求数量,同时Zset的数据结构提供range方法可以获取两个时间戳范围内有多少个请求。
具体实现代码如下:
public Response limitFlow(){
Long currentTime = new Date().getTime();
System.out.println(currentTime);
if(redisTemplate.hasKey("limit")) {
Integer count = redisTemplate.opsForZSet().rangeByScore("limit", currentTime - intervalTime, currentTime).size();
// intervalTime是限流的时间
System.out.println(count);
if (count != null && count > 5) {
return Response.ok("每分钟最多只能访问5次");
}
}
redisTemplate.opsForZSet().add(
"limit",UUID.randomUUID().toString(),currentTime);
return Response.ok("访问成功");
}zset的实现方式也比较简单,每N秒可以产生M个请求,缺点是zset会随着构建数据不断增长。
基于Redis的令牌桶算法
我们根据前文介绍的令牌桶可以得知,当输出的速率大于输入的速率,会出现“溢出”的情况。guava通过acquire 方法挂起等待获取令牌,这种方法虽然可以做到精确的流量控制,但是会出现“前人挖坑,后人埋坑”的情况,并且只能用于单JVM内存。
面对分布式项目,我们可以通过Redis的List结构进行改造,实现方式同样非常简单。
依靠List的leftPop来获取令牌:
// 输出令牌
public Response limitFlow2(Long id) {
Object result = redisTemplate.opsForList().leftPop("limit_list");
if(result == null){
return Response.ok("当前令牌桶中无令牌");
}
return Response.ok(articleDescription2);
}
leftPop语法:LPOP key [count]移除并返回存储在.key的列表中的第一个元素。默认情况下,该命令从列表的开头弹出一个元素。 案例:
redis> RPUSH mylist "one" "two" "three" "four" "five" (integer) 5
redis> LPOP mylist "one" redis> LPOP mylist 2 1) "two" 2) "three"再依靠Java的定时任务,定时往List中rightPush令牌,为了保证分布式环境的强唯一性,可以使用redission生成唯一ID或者使用雪花算法生成ID,这样的结果更为靠谱。
上面代码的集成可以使用AOP或者Filter中加入限流代码即可。较为完美的方案是依靠Redis的限流,这样可以做到部署多个JVM也可以进行正常工作。
如果是单JVM则使用UUID的结果即可:
// 10S的速率往令牌桶中添加UUID,只为保证唯一性
@Scheduled(fixedDelay = 10_000,initialDelay = 0)
public void setIntervalTimeTask(){
redisTemplate.opsForList().rightPush(
"limit_list",UUID.randomUUID().toString());
}令牌桶算法VS漏桶算法VSRedis限流
漏桶算法的出水速度是恒定的,那么意味如果出现大流量会把大部分请求同时丢弃(水溢出)。令牌桶的算法也是恒定的,请求获取令牌没有限制,对于大流量可以短时间产生大量令牌,同样获取令牌的过程消耗不是很大。
Redis的限流不依赖JVM,是较为靠谱和推荐的方式,具体的实现可以依赖Redis本身的数据结构和Redis命令天然的原子性实现,唯一需要注意的是在具体编程语言接入的时候能否写出具备线程安全的代码。
小结
注意本文介绍的限流算法都是在JVM级别的限流,限流的令牌都是在内存中生成的,需要注意在分布式的环境下不能使用,如果要分布式限流,可以用redis限流。
使用guava限流是比较常见的,而Redis的限流是依赖中间件完成的,实现起来更为简单也更推荐。
Redis消息队列
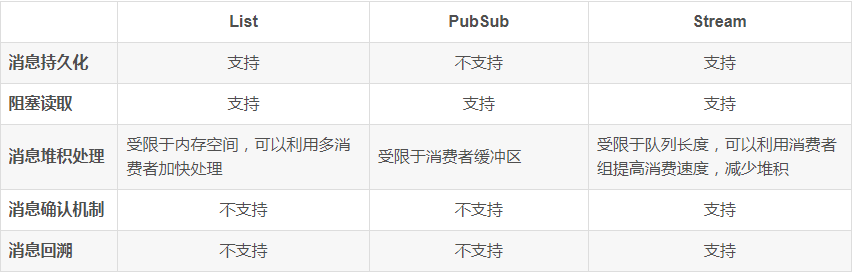
Redis提供了三种不同的方式来实现消息队列:
list结构:基于List结构模拟消息队列
PubSub:基本的点对点消息模型
Stream:比较完善的消息队列模型
基于List结构模拟消息队列
LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。
它是 RPOP key 命令的阻塞版本,当给定列表内没有任何元素可供弹出的时候,连接将被 BRPOP 命令阻塞,直到等待超时或发现可弹出元素为止。
优点:
利用Redis存储,不受限于JVM内存上限
基于Redis的持久化机制,数据安全性有保证
可以满足消息有序性
缺点:
无法避免消息丢失
只支持单消费者
基于PubSub的消息队列
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
命令:
SUBSCRIBE channel [channel] :订阅一个或多个频道
PUBLISH channel msg :向一个频道发送消息
PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
pattern:
?:匹配一个字符
*:匹配0或多个字符
[a,e]:匹配括号内存在的字符
优点:
采用发布订阅模型,支持多生产、多消费
缺点:
不支持数据持久化
无法避免消息丢失
消息堆积有上限,超出时数据丢失
基于Stream的消息队列
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
发送消息的命令:

NOMKSTREAM:如果队列不存在,是否自动创建队列 默认是自动创建
[MAXLEN|MINID [=|~] threshold [LIMIT count]]:设置消息队列的最大消息数量
|ID:消息的唯一id, 代表由Redis自动生成。格式是 "时间戳-递增数字" ,例如 "1644804662707-0"
field value [field value ...]:发送到队列中的消息,称为Entry。 格式就是多个key-value键值对
读取消息的方式之一:XREAD

COUNT count:每次读取消息的最大数量
BLOCK milliseconds:当没有消息时,是否阻塞、阻塞时长
STREAMS key [key ...]:要从哪个队列读取消息,key就是队列名
ID [ID ...]:起始id,只返回大于该ID的消息,0:代表从第一个消息开始,$:代表从最新的消息开始
STREAM类型消息队列的XREAD命令特点:
消息可回溯
一个消息可以被多个消费者读取
可以阻塞读取
有消息漏读的风险
基于Stream的消息队列-消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。
特点:

创建消费者组:

key:队列名称
groupName:消费者组名称
ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
MKSTREAM:队列不存在时自动创建队列
给指定的消费者组添加消费者 :
GROUP CREATECONSUMER key groupname consumername删除指定的消费者组:
XGROUP DESTORY key gruopName删除消费者组中的指定消费者 :
GROUP DELCONSUMER key groupname consumername从消费者组读取消息:

group:消费组名称
consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
count:本次查询的最大数量
BLOCK milliseconds:当没有消息时最长等待时间
NOACK:无需手动ACK,获取到消息后自动确认
STREAMS key:指定队列名称
ID:获取消息的起始ID:
">":从下一个未消费的消息开始
其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始。
STREAM类型消息队列的XREADGROUP命令特点:
消息可回溯
可以多消费者争抢消息,加快消费速度
可以阻塞读取
没有消息漏读的风险
有消息确认机制,保证消息至少被消费一次