🍖 Introduction
一、什么是机器学习 Machine Learning
① 定义
🔵 Arthur Samuel(1959):Machine Learning : Field of study that gives computers the ability to learn without being explicitly programmed. 在没有明确设置的情况下,使计算机具有学习能力的研究领域。
⭐ Tom Mitchell(1998):Well-posed Learning Problem:A computer program is said to learn from experience E with respect to some task T and some performance measure P,if its performance on T,as measured by P,improves with experience E. 一个适当的学习问题定义如下:计算机程序从经验 E (程序与自己下上万次跳棋)中学习,解决某一任务 T (玩跳棋),进行某一性能度量 P (与新对手玩跳棋时赢的概率),通过 P 测定在 T 上的表现因经验 E 而提高。
🍉 更通俗来说:机器学习所研究的主要内容,是关于在计算机上从数据中产生 “模型” 的算法,即 “学习算法” 。有了学习算法,我们把经验数据提供给它,它就能基于这些数据产生模型;在面对新的情况时(例如看到一个没剖开的西瓜),模型会给我们提供相应的判断(例如好瓜)。
📜 本书用 "模型" 泛指从数据中学得的结果。
有文献用"模型"指全局性结果,而用"模式"指局部性结果
② 每节小问
❓ 基于 Tom Mitchell 对于机器学习的定义,提出一个问题:
Suppose your email program watches which emails you do or do not mark as spam(垃圾邮件),and based on that learns how to better filter spam. What is the task T in this setting? 假设你的邮箱正在观察你将哪些邮件标记为垃圾邮件,并基于此学习如何更好的过滤邮件,那么在这里任务 T 是什么?
✅ Classifying emails as spam or not spam 把邮件分类为垃圾邮件和非垃圾邮件:这是任务 T
❌ Watching you label email as spam or not spam 是否把邮件标记为垃圾邮件:这是经验 E
❌ The number(or fraction) of eamils correctly classified as spam/not spam:正确归类邮件的数量/比例:这是性能度量 P
即任务 T 在得到经验 E 之后会提高性能度量 P
③ 机器学习算法概览
📜 Machine Learning algorithms:
Supervised learning 监督学习:我们教计算机学习
Unsupervised learning 无监督学习:计算机自己学习
Others:Reinforcement learning 强化学习,recommender systems 推荐系统
🔖 Also talk about : Practical advice for applying for applying learning algorithms 本课程中还会讲到应用学习算法时的实际建议
二、基本术语
🍉 要进行机器学习,先要有数据。假定我们收集了一批关于西瓜的数据,例如(色泽=青绿; 根蒂=蜷缩; 敲声=浊响),(色泽=乌黑; 根蒂=稍蜷; 敲声=沉闷),(色泽=浅白; 根蒂=硬挺; 敲声=清脆),……,每对括号内是一记录,“=” 意思是"取值为"
数据集 data set:这组记录的集合称为一个数据集
样本 sample / 示例 instance / 特征向量 feature vector:数据集中的每条记录时关于一个事件或对象的描述,称为一个示例 或 样本 或 特征向量
属性 attribute / 特征 feature:反映事件或对象在某方面的表现或性质的事项,例如 “色泽” “根蒂” 等称为 属性 或 特征
属性值 attribute value:属性上的取值称为 属性值。例如 “乌黑”
属性空间 attribute space / 样本空间 sample space / 输入空间:属性张成的空间称为属性空间 或 样本空间 或 输入空间。例如把 “色泽” “根蒂” “敲声” 作为三个坐标轴,则它们张成一个用于描述西瓜的三维空间,每个西瓜都可在这个空间中找到自己的坐标位置。由于空间中的每个点对应一个坐标向量,因此我们也把 样本/示例 称为一个"特征向量"。
维数 dimensionality:每个样本由 d 个属性描述,则 d 称为样本的维数
学习 learning / 训练 training:从数据中学得模型的过程称为"学习"或"训练",这个过程通过执行某个学习算法来完成
训练数据 training data:训练过程中使用的数据称为训练数据
训练样本 training sample:训练数据中的每个样本称为一个训练样本
训练集 training set:训练样本组成的集合称为 训练集
假设 hypothesis:学得模型对应了关于数据的某种潜在的规律,因此亦称"假设"
真相 / 真实 ground-truth:这种潜在规律自身,则称为"真相"或"真实"。学习过程就是为了找出或逼近真相
标签 / 标记 label:如果希望学得一个能帮助我们判断没剖开的是不是"好瓜"的模型,仅有前面的示例数据显然是不够的。要建立这样的关于 "预测" (prediction)模型,我们需获得训练样本的"结果"信息,例如 "((色泽=青绿; 根蒂=蜷缩; 敲声=浊响),好瓜)"。这里关于示例结果的信息,例如"好瓜",称为"标记 / 标签"。
根据训练数据是否有标签,学习任务可分为监督学习和无监督学习。
样例 example:有了标签信息的示例,则称为样例。一般的,用 $(x_i,y_i)$ 表示第 i 个样例,其中 $y_i$ 时是示例 $x_i$ 的标签
泛化能力 generalization:机器学习的目标是使学得的模型能很好地适用于"新样本",而不是仅仅在训练样本上工作得很好;即便对聚类这样的无监督学习任务,我们也希望学得的簇划分能适用于没在训练集中出现的样本。学得模型适用于新样本的能力,称为"泛化"能力。
三、监督学习概述 Supervised Learning
① 定义
🔴 Supervised learning:We give the algorithm a data set,in which the "right answers" were given,and the task of the algorithm was to just produce more of these right answers. 我们给算法一个数据集,其中包含了正确答案,即这些数据是带有标签的,算法的目的就是给出更多的正确答案。
② 回归问题 Regression
💬 举例来说,比如有个人想要卖房子,他需要结合自己房子的大小来评估房子能卖多少钱。此时我们已经有了一些正确的数据集(房子大小和房价的对应关系),如下图所示:
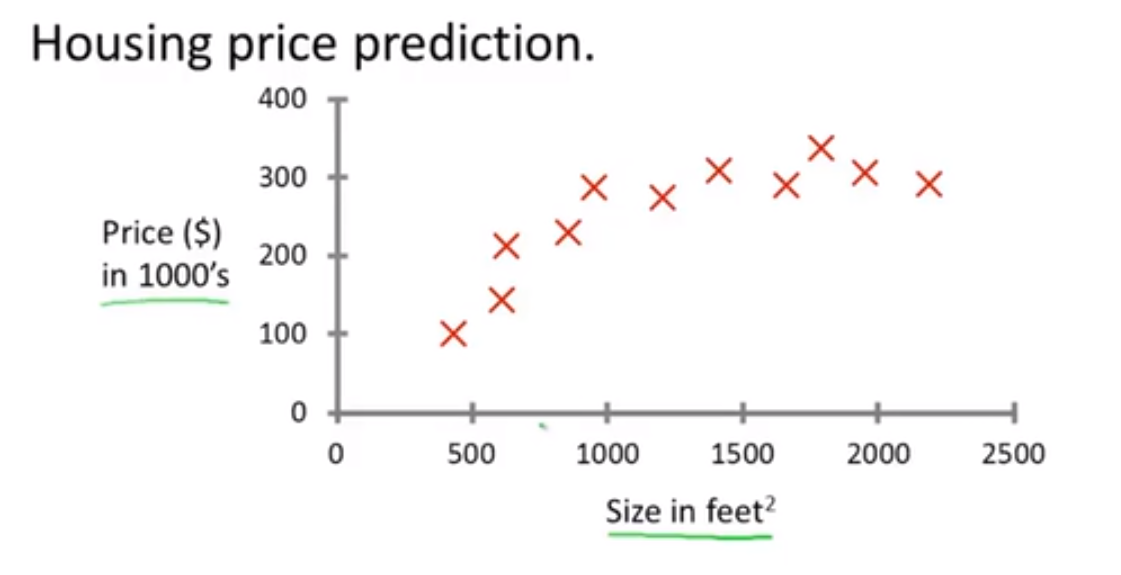
那么学习算法能做到的一件事情就是用一条直线或者二次函数来拟合数据,从而预测出房子能卖多少钱。后面我们要讨论的问题就是选择使用直线拟合数据还是选用二次函数来拟合数据。
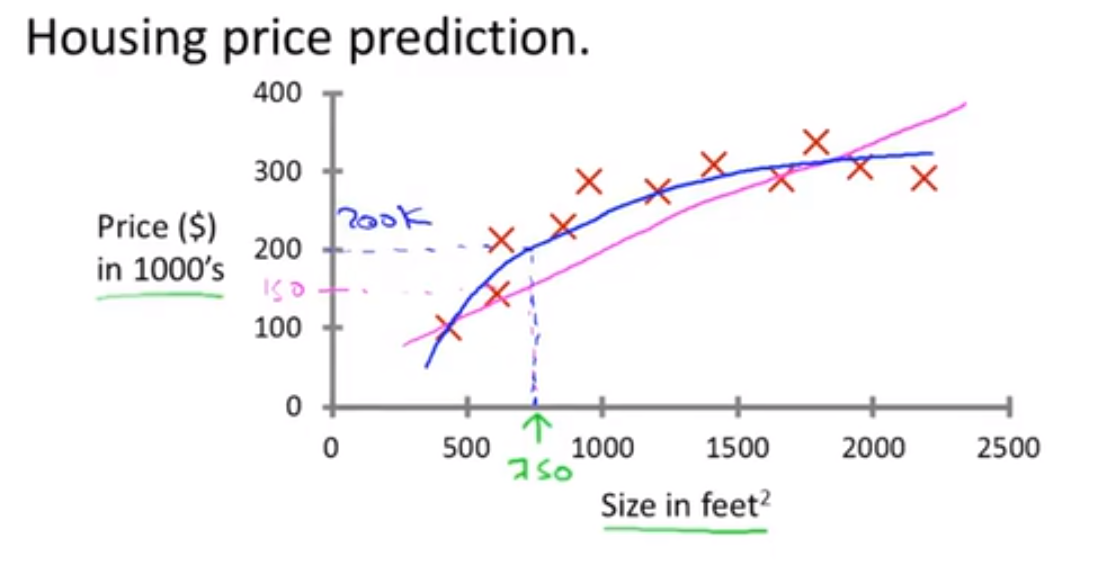
🔴 用更专业的术语来定义,它也被称为回归问题 Regression:回归的目标就是 Predict continuous valued output 预测连续的数值输出
③ 分类问题 Classification
💬 我们来看下一个例子:比如我们要预测乳腺癌是恶性的还是良性的,假设此时我们已有一些正确的数据集(肿瘤的大小 tumor size 和肿瘤良/恶性 malignant 的对应关系),如下图所示:
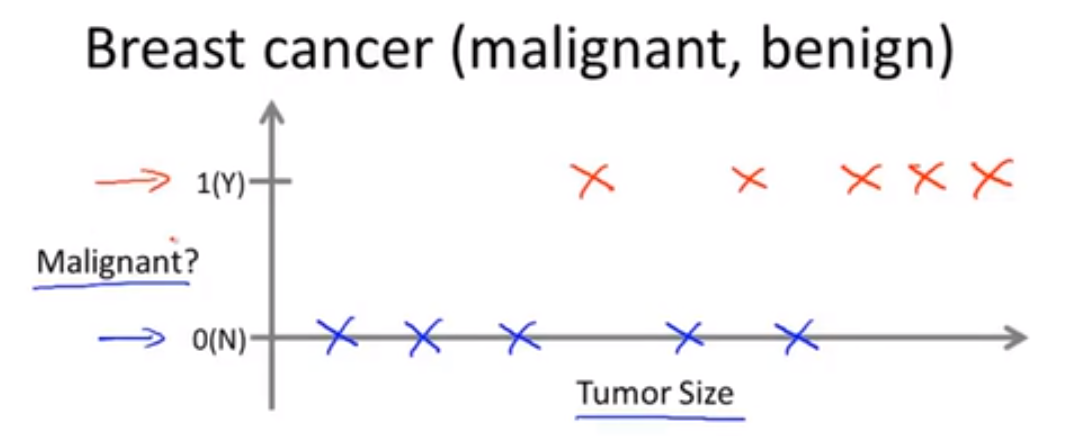
那么机器学习的目标就是根据肿瘤的大小估计出肿瘤是良性还是恶性的概率。用更专业的术语来讲,这就是一个分类问题 Classification Problem。
🔴 分类是指:我们设法预测一个离散值输出,0 或 1 (良性 或 恶性),有时你也有两个以上的可能的输出值,因此,你可能要设法预测离散值0、1、2...。即分类的目的就是预测离散值输出
在分类问题中,有另一种方法来绘制这些数据,如下图所示:
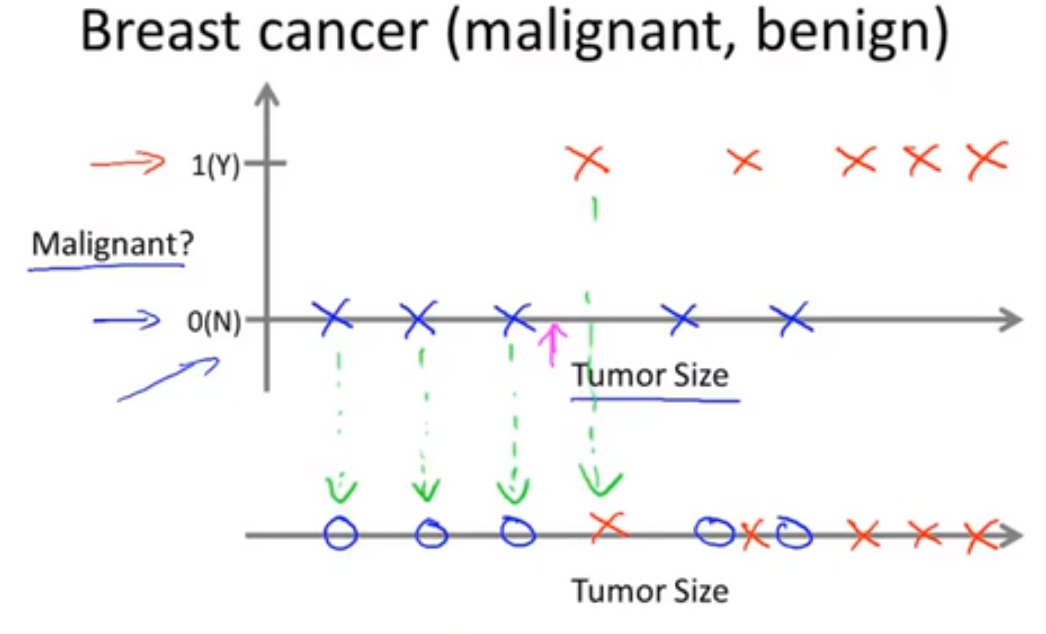
在这个例子中,我们只使用了一个特征或者说属性,即肿瘤的大小,来预测肿瘤是恶性的还是良性的。
在其他的机器学习问题中,我们会有多个特征、多个属性,如下例所示:
💬 假设我们不仅知道肿瘤的大小,还知道病人的年纪,我们所拥有的数据集用下图所示:
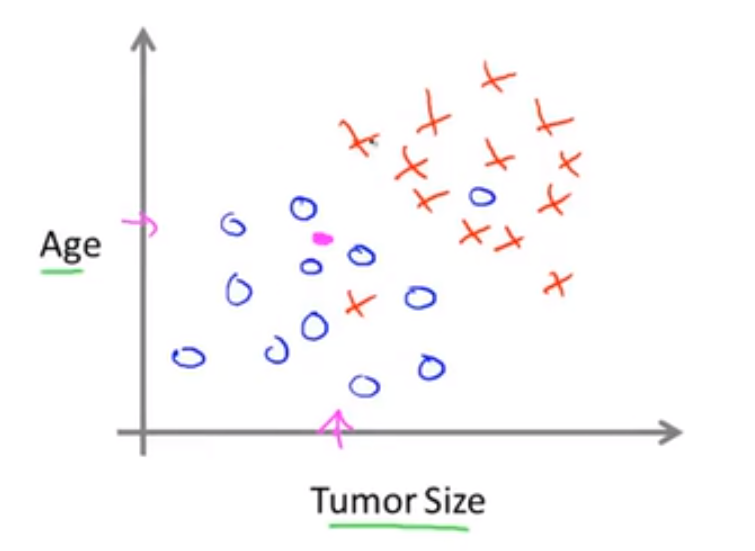
学习算法所需要做的就是在数据上拟合出一条直线将恶性肿瘤和良性肿瘤分隔开来,如下图所示:
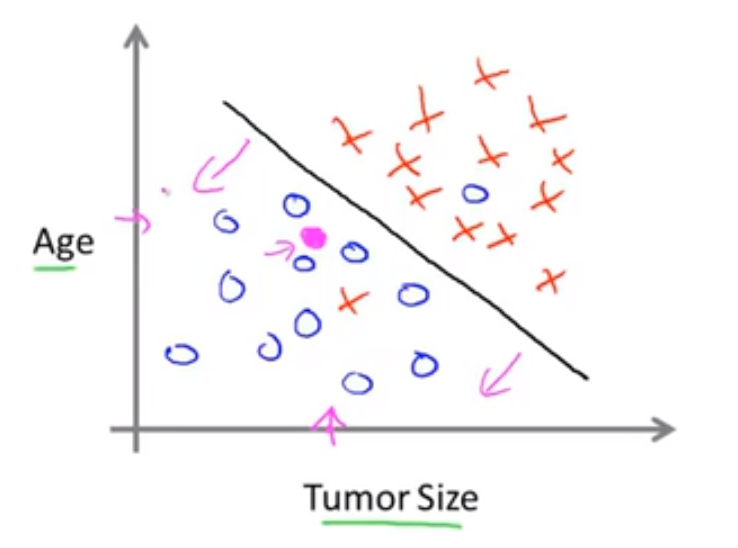
显然,在现实生活中,我们所需要处理的特征远不止一个两个。对于某些学习问题来说,我们想要的不是使用三个还是五个特征,而是无穷多的特征、无穷多的属性,因此我们的学习算法需要使用很多的属性或特征或线索来做预测,那么如何来处理无穷多的特征呢?如何在计算机中存储无穷多数量的事物呢?
④ 每节小问
❓ 基于本节的学习,提出一个问题:
判断下面两种情况属于分类问题还是回归问题:
Problem1:You have a large inventory of identical items. You want to predict how many of these items will sell over the next 3 months. 你有很多同一件货物的库存,假设你有几千件相同的货物要卖,你想预测在接下来的三个月内,你能卖出多少件。
👉 Regression Problem 回归问题:把要卖的货物数量看成一个连续的值
Problem2:You'd like software to examine individual customer accounts, adn for each account decide if it has been hacked/compromise. 你有很多用户,你想要写一个软件,来检查每一个客户的账户,判断这个账户是否被入侵或破坏
👉 Classification Problem 分类问题:设置预测的值为 0 表示账户没有被入侵,1 表示被入侵
四、无监督学习概述 Unsupervised Learning
① 定义
在监督学习中,每个样本都被标明为(labled)阳性样本或者阴性样本,我们已被清楚的告知了什么是正确答案(即肿瘤是良性还是恶性)。
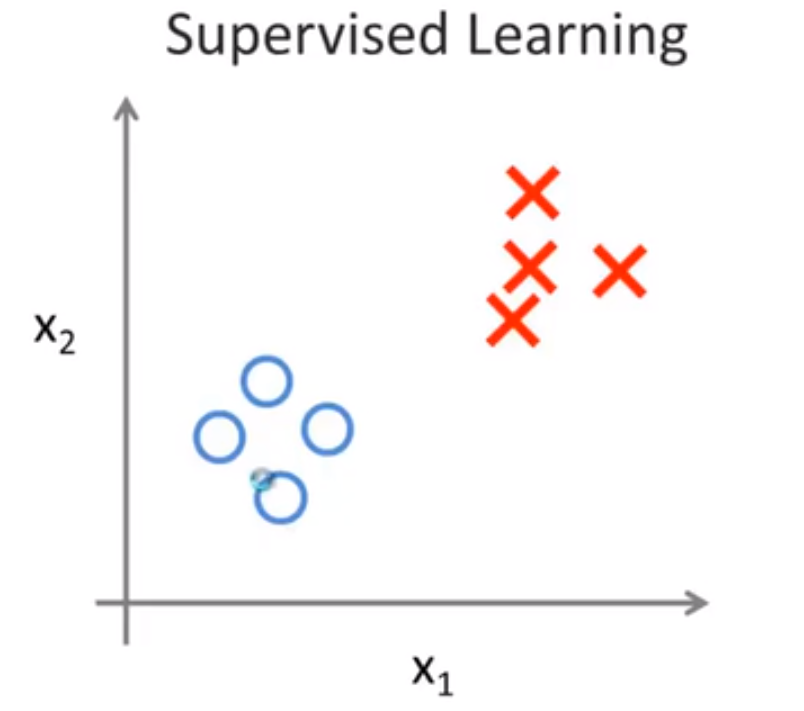
🔴 而对于无监督学习来说,我们的数据集没有任何标签,或者说都具有相同的标签或者没有标签,即我们不知道什么是正确答案。我们拿到这个数据集,不知道要拿它做什么,也不知道每个数据点究竟是什么,我们只被告知这里有一个数据集,你能在其中找到某种结构来适配这些数据吗?
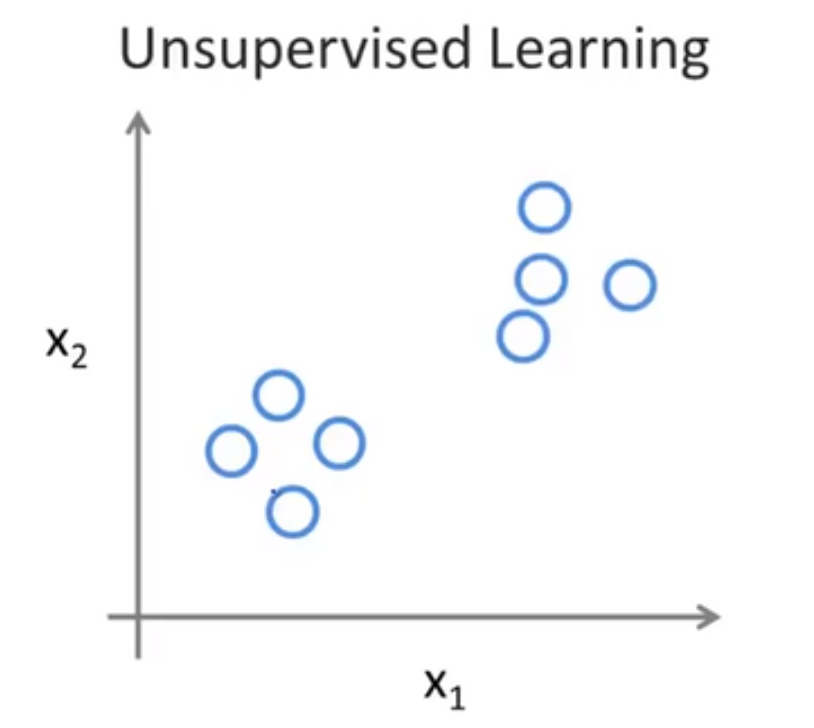
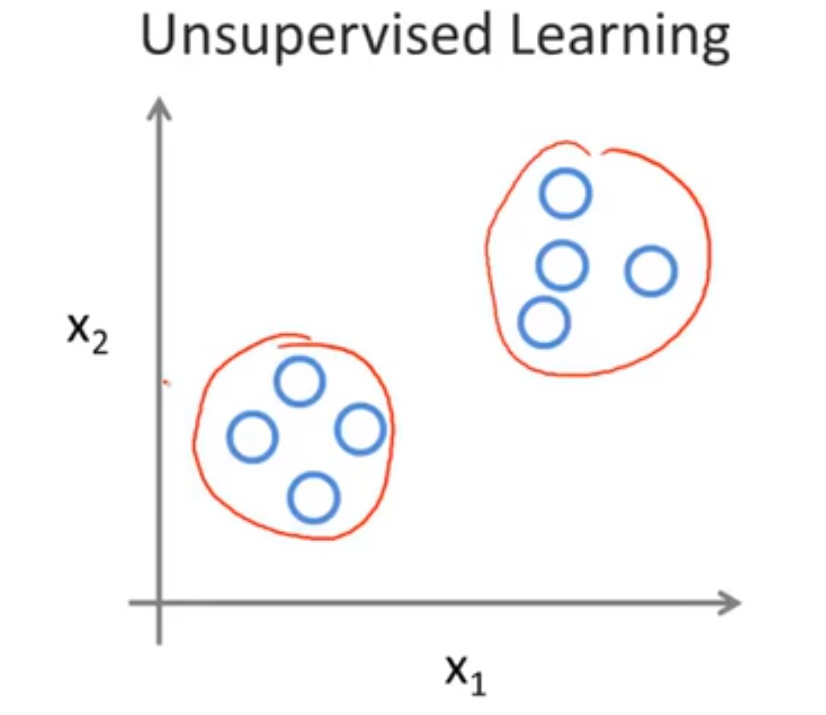
② 聚类算法 Clustering
对于给定的数据集,无监督学习算法可能将该数据集分成两个不同的簇,这就是聚类算法 clustering algorithm
💬 一个应用聚类算法的典型例子就是谷歌新闻,谷歌新闻会搜索成千上万的新闻,然后自动的对它们进行分簇,有关同一主题的新闻被分在同一类,比如关于新冠病毒的新闻放在同一类。
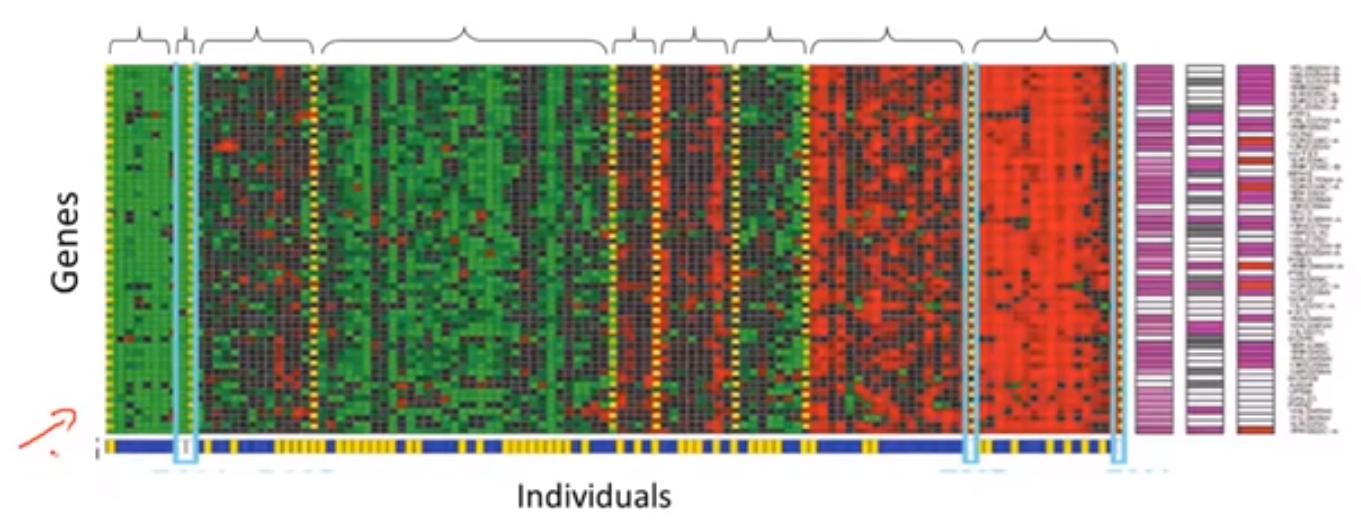
起始聚类算法和无监督学习算法也可以被用于许多其他的问题,这里我们举个它在基因组学中的应用:
💬 下图是一个 DNA 微阵列数据,基本思想是给定一组不同的个体,对于每个个体,检测它们是否拥有某个特定的基因,也就是要检测,特定基因的表达程度。这些颜色红、绿、灰等展示了不同的个体拥有特定基因的程度。然后我们所能做的就是运行一个聚类算法,把不同的个体,归入不同的类,或归入不同类型的人。
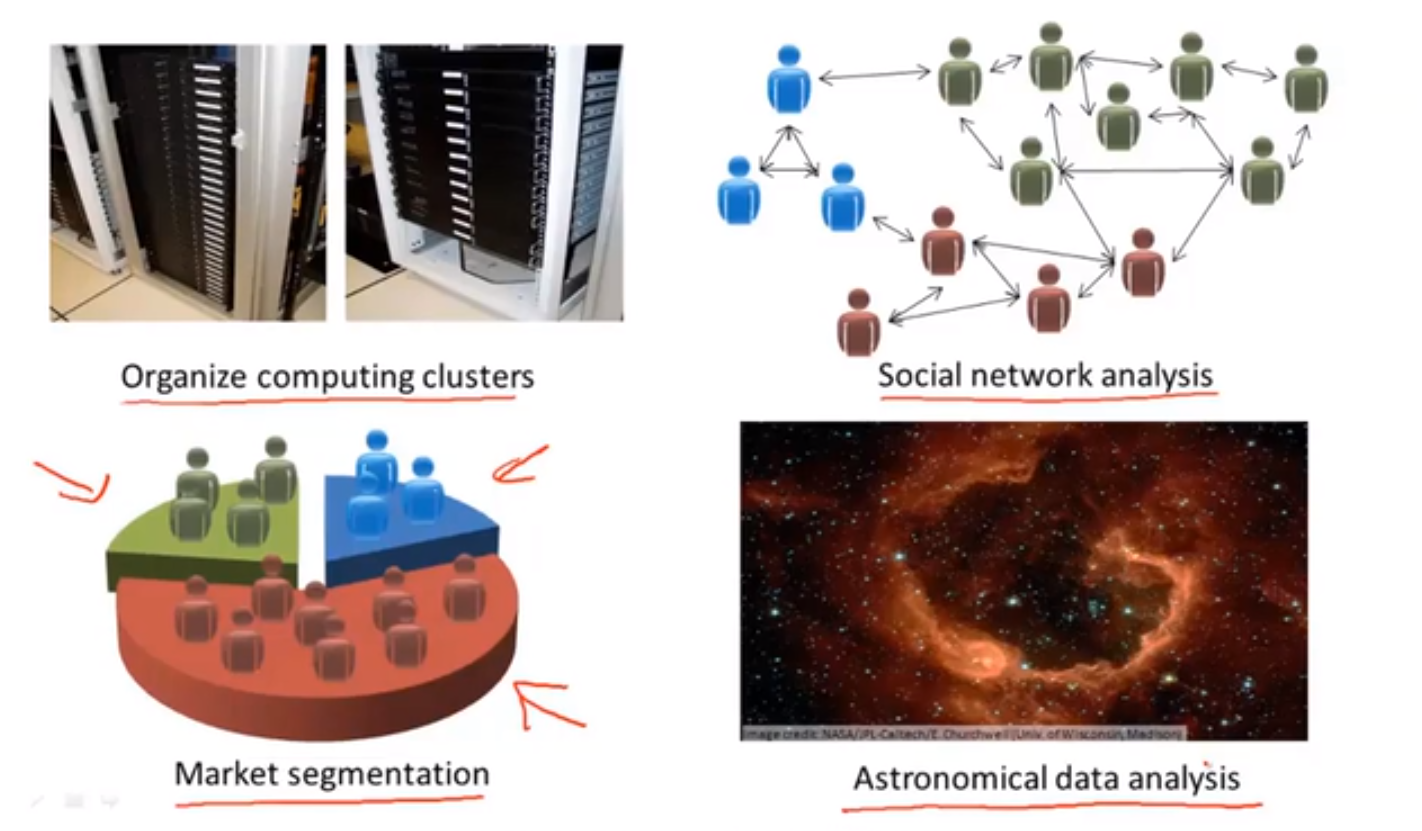
💬 聚类算法还被广泛应用于如下场合:
聚类只是无监督学习的一种,现在我们来介绍下一种:鸡尾酒会算法
③ 鸡尾酒会算法 Cocktail party
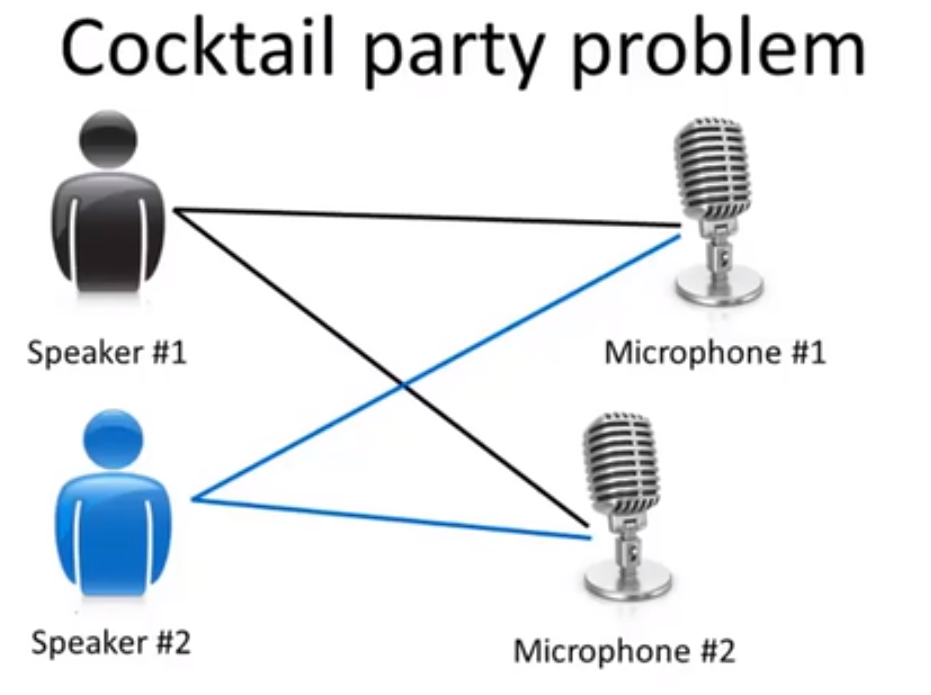
🔵 首先介绍一下鸡尾酒会问题 Cocktail party problem:有一个宴会,一屋子的人,因为有许多人在同时说话,有许多声音混杂在一起,你几乎很难听清你面前的人说的话。假设一个鸡尾酒会只有两个人,同时说话,我们将两个麦克风放在房间里,且这两个麦克风与两个人的距离不同,每个麦克风记录了来自两人声音的不同组合。我们能做的就是把这两个录音交给一种无监督学习算法,称为 "鸡尾酒会算法 cocktail party algorithm",让算法帮你找出数据的结构,该算法就会分离出这两个被混叠在一起的声音。
鸡尾酒会算法的 Matlab 实现:
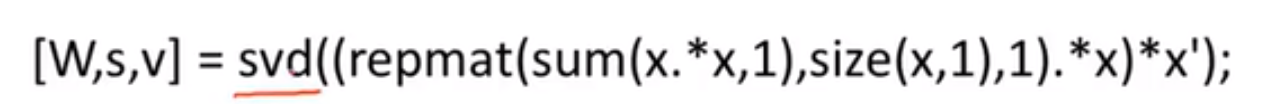
④ 每节小问
Of the following examples, which would you address using an unsupervised learning algorithm? 判断下面哪些是无监督学习算法:
❌ Given email labeled as spam/not spam, learn a spam filter. 垃圾邮件
✅ Given a set of news articles found on the web, group them into set of articles about the same story. 新闻归类
✅ Given a database of customer data, automatically discover market segments and group customers into different market segments. 市场划分
❌ Given a database of patients diagnosed as either having diabetes (糖尿病) or not, learn to classify new patients as having diabetes or not. 糖尿病预测
✍ Quiz — Week 1 | 1 Introduction
🔊 本笔记中的所有 Quiz 都来源于吴恩达老师在 Coursera 上的机器学习课程。
① 第 1 题
A computer program is said to learn from experience E with respect to some task T and some performance measure P if its performance on T, as measured by P, improves with experience E. Suppose we feed a learning algorithm a lot of historical weather data, and have it learn to predict weather. What would be a reasonable choice for P? 一个计算机程序从经验E中学习任务T,并用P来衡量表现。并且,T的表现P随着经验E的增加而提高。 假设我们给一个学习算法输入了很多历史天气的数据,让它学会预测天气。什么是P的合理选择?
The process of the algorithm examining a large amount of historical weather data. 计算大量历史气象数据的过程
✅ The probability of it correctly predicting a future date's weather. 正确预测未来日期天气的概率
None of these.
The weather prediction task. 天气预报任务
② 第 2 题
Suppose you are working on weather prediction, and your weather station makes one of three predictions for each day's weather: Sunny, Cloudy or Rainy. You'd like to use a learning algorithm to predict tomorrow's weather. Would you treat this as a classification or a regression problem? 假设你正在做天气预报,并使用算法预测明天气温(摄氏度/华氏度),你会把这当作一个分类问题还是一个回归问题?
Regression
✅ Classification
③ 第 3 题
Suppose you are working on stock market prediction, and you would like to predict the price of a particular stock tomorrow (measured in dollars). You want to use a learning algorithm for this. Would you treat this as a classification or a regression problem? 假设你在做股市预测。你想预测某家公司是否会在未来7天内宣布破产(通过对之前面临破产风险的类似公司的数据进行训练)。你会把这当作一个分类问题还是一个回归问题?
Classification
✅ Regression
④ 第 4 题
Some of the problems below are best addressed using a supervised learning algorithm, and the others with an unsupervised learning algorithm. Which of the following would you apply supervised learning to? (Select all that apply.) In each case, assume some appropriate dataset is available for your algorithm to learn from. 下面的一些问题最好使用有监督的学习算法来解决,而其他问题则应该使用无监督的学习算法来解决。以下哪一项你会使用监督学习?(选择所有适用的选项)在每种情况下,假设有适当的数据集可供算法学习。
✅ In farming, given data on crop yields over the last 50 years, learn to predict next year's crop yields. 在农业领域,根据过去50年作物产量的数据,学会预测明年的作物产量。
Given a large dataset of medical records from patients suffering from heart disease, try to learn whether there might be different clusters of such patients for which we might tailor separate treatments. 鉴于心脏病患者的医疗记录量很大,请尝试了解是否存在不同的此类患者群,我们可以针对这些患者进行单独治疗。
✅ Given data on how 1000 medical patients respond to an experimental drug (such as effectiveness of the treatment, side effects, etc.), discover whether there are different categories or "types" of patients in terms of how they respond to the drug, and if so what these categories are. 给定 1000 名医疗患者对实验药物(如治疗效果、副作用等)的反应数据,发现患者在药物反应方面是否有不同类别或"类型",如果是,这些类别是什么。
✅ Examine a web page, and classify whether the content on the web page should be considered "child friendly" (e.g., non-pornographic, etc.) or "adult." 检查网页,并分类网页上的内容是否应被视为"儿童友好"(例如,非色情等)或"成人"。
⑤ 第 5 题
Which of these is a reasonable definition of machine learning?
Machine learning is the science of programming computers. 机器学习是计算机编程的科学。
✅ Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed. 机器学习是使计算机无需明确编程即可学习的研究领域。
Machine learning is the field of allowing robots to act intelligently. 机器学习是允许机器人智能行动的领域。
Machine learning learns from labeled data. 机器学习从标记的数据中学习。
📚 References
👘《周志华 - 机器学习》
