🍩 神经网络:前向传播算法 Neural Networks
一、非线性假设 Non-linear Hypotheses
我们之前学的,无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时,计算的负荷会非常大。
下面是一个例子:
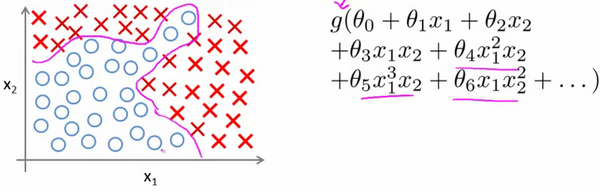
当我们使用 x 的多次项式进行预测时,我们可以应用的很好。 之前我们已经看到过,使用非线性的多项式项,能够帮助我们建立更好的分类模型。假设我们有非常多的特征,例如大于100个变量,我们希望用这100个特征来构建一个非线性的多项式模型,结果将是数量非常惊人的特征组合,即便我们只采用两两特征 $(x_1x_2 + x_1x_3 + x_1x_4 + ... + x_2x_3 + x_2x_4 + ... + x_{99}x_{100})$ 的组合,我们也会有接近5000个组合而成的特征。这对于一般的逻辑回归来说需要计算的特征太多了。
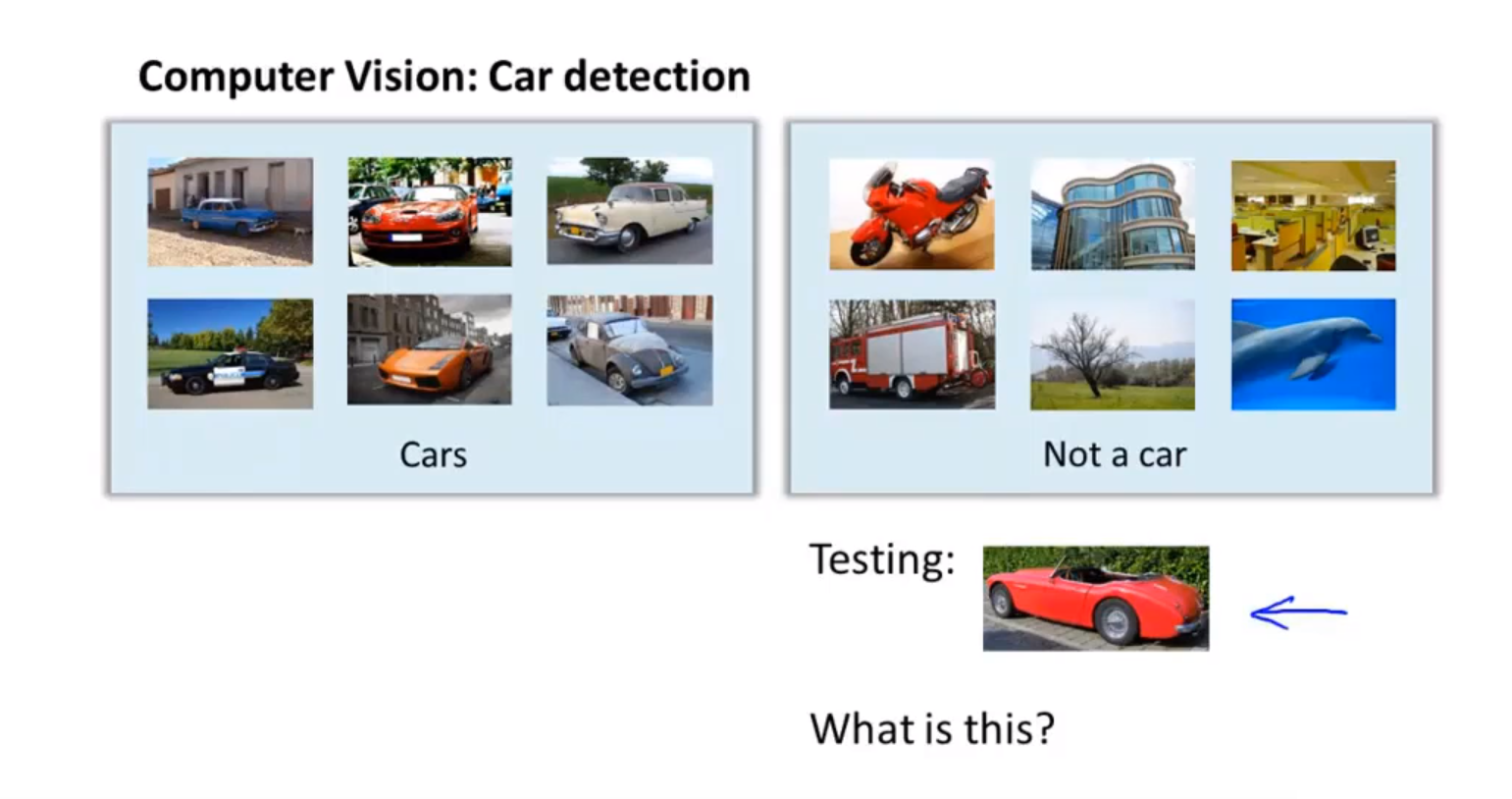
假设我们希望训练一个模型来识别视觉对象(例如识别一张图片上是否是一辆汽车),我们怎样才能这么做呢?一种方法是我们提供一个带标签的样本集,其中一些样本是各类汽车,另一部分不是汽车,将这个样本集输入给学习算法,以训练出一个分类器。然后我们进行测试,输入一幅新的图片,让分类器判定这是什么东西。
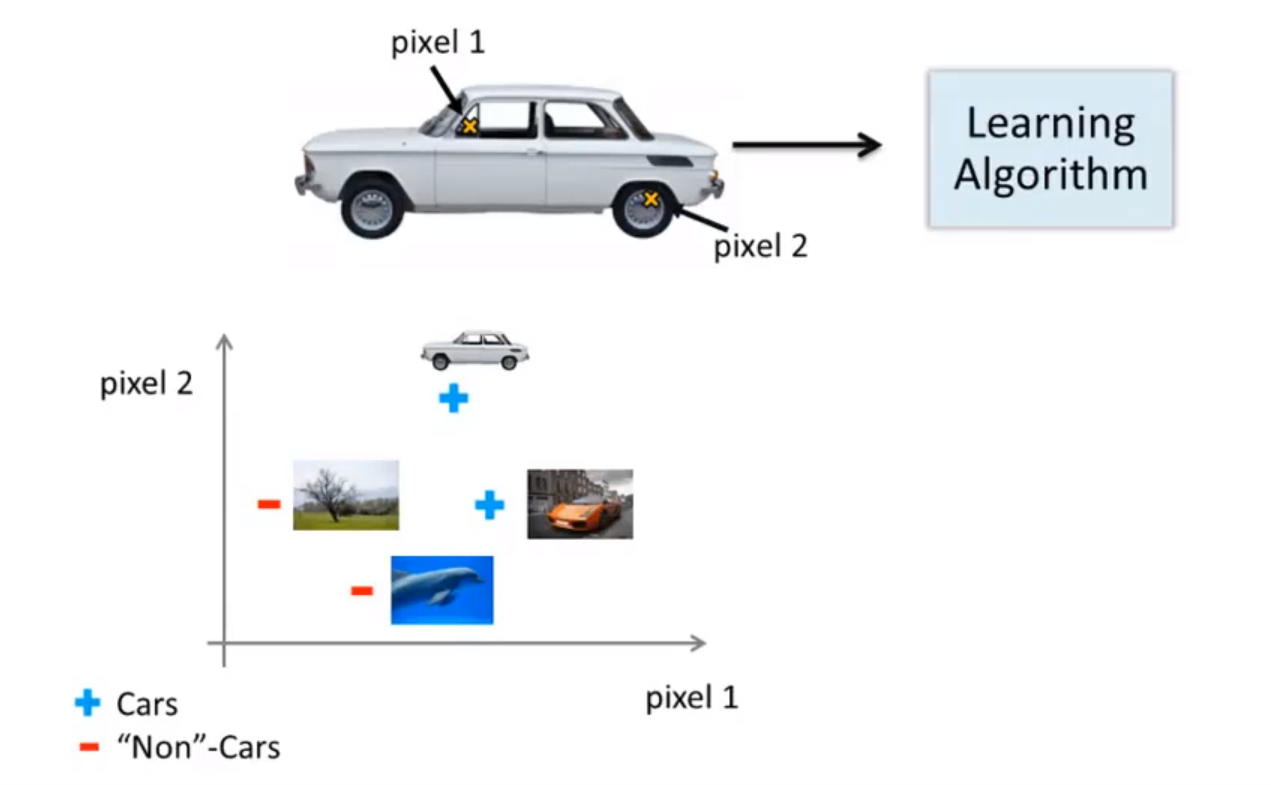
假如我们只选用灰度图片,每个像素则只有一个值(而非 RGB值),我们可以选取图片上的两个不同位置上的两个像素,然后训练一个逻辑回归算法利用这两个像素的值来判断图片上是否是汽车:
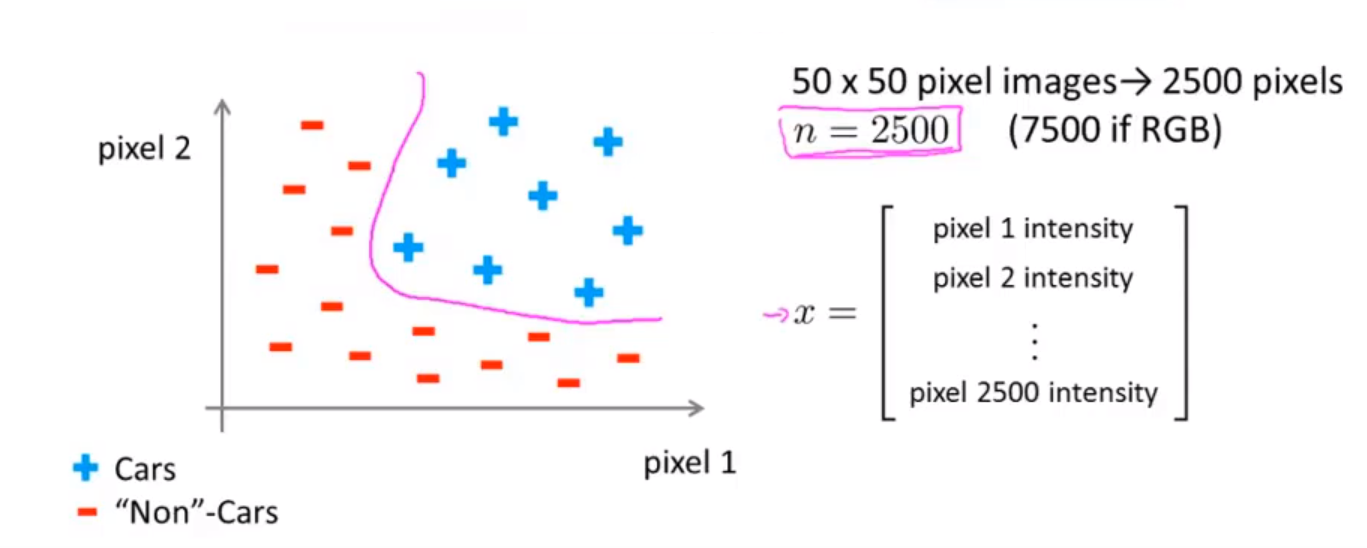
假使我们采用的都是50x50像素的小图片,并且我们将所有的像素视为特征,则会有 2500个特征,如果我们要进一步将两两特征组合构成一个多项式模型,则会有约 $2500^2 / 2$ 个(接近3百万个)特征。普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们就需要神经网络。
二、神经元和大脑 Neurons and the Brain
神经网络是一种很古老的算法,它最初产生的目的是制造能模拟大脑的机器。
神经网络逐渐兴起于二十世纪八九十年代,应用得非常广泛。但由于各种原因,在90年代的后期应用减少了。但是近几年来,神经网络又东山再起了。其中一个原因是:神经网络是计算量有些偏大的算法。然而由于近些年计算机的运行速度变快,才足以真正运行起大规模的神经网络。正是由于这个原因和其他一些我们后面会讨论到的技术因素,如今的神经网络对于许多应用来说是最先进的技术。
我们能学习数学,学着做微积分,而且大脑能处理各种不同的令人惊奇的事情。似乎如果你想要模仿它,你得写很多不同的软件来模拟所有这些五花八门的奇妙的事情。不过能不能假设大脑做所有这些,不同事情的方法,不需要用上千个不同的程序去实现。相反的,大脑处理的方法,只需要一个单一的学习算法就可以了?
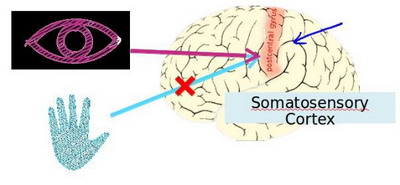
大脑的这一部分这一小片红色区域是你的听觉皮层,你现在正在理解我的话,这靠的是耳朵。耳朵接收到声音信号,并把声音信号传递给你的听觉皮层,正因如此,你才能明白我的话。
神经系统科学家做了下面这个有趣的实验,把耳朵到听觉皮层的神经切断。在这种情况下,将其重新接到一个动物的大脑上,这样从眼睛到视神经的信号最终将传到听觉皮层。如果这样做了。那么结果表明听觉皮层将会学会“看”。这里的“看”代表了我们所知道的每层含义。所以,如果你对动物这样做,那么动物就可以完成视觉辨别任务,它们可以看图像,并根据图像做出适当的决定。它们正是通过脑组织中的这个部分完成的。
下面再举另一个例子,这块红色的脑组织是你的躯体感觉皮层,这是你用来处理触觉的,如果你做一个和刚才类似的重接实验,那么躯体感觉皮层也能学会“看”。这个实验和其它一些类似的实验,被称为神经重接实验,从这个意义上说,如果人体有同一块脑组织可以处理光、声或触觉信号,那么也许存在一种学习算法,可以同时处理视觉、听觉和触觉,而不是需要运行上千个不同的程序,或者上千个不同的算法来做这些大脑所完成的成千上万的美好事情。也许我们需要做的就是找出一些近似的或实际的大脑学习算法,然后实现它大脑通过自学掌握如何处理这些不同类型的数据。在很大的程度上,可以猜想如果我们把几乎任何一种传感器接入到大脑的几乎任何一个部位的话,大脑就会学会处理它。
下面再举几个例子:

这张图是用舌头学会“看”的一个例子。它的原理是:这实际上是一个名为BrainPort的系统,它现在正在FDA (美国食品和药物管理局)的临床试验阶段,它能帮助失明人士看见事物。它的原理是,你在前额上带一个灰度摄像头,面朝前,它就能获取你面前事物的低分辨率的灰度图像。你连一根线到舌头上安装的电极阵列上,那么每个像素都被映射到你舌头的某个位置上,可能电压值高的点对应一个暗像素电压值低的点。对应于亮像素,即使依靠它现在的功能,使用这种系统就能让你我在几十分钟里就学会用我们的舌头“看”东西。

这是第二个例子,关于人体回声定位或者说人体声纳。你有两种方法可以实现:你可以弹响指,或者咂舌头。不过现在有失明人士,确实在学校里接受这样的培训,并学会解读从环境反弹回来的声波模式—这就是声纳。如果你搜索YouTube之后,就会发现有些视频讲述了一个令人称奇的孩子,他因为癌症眼球惨遭移除,虽然失去了眼球,但是通过打响指,他可以四处走动而不撞到任何东西,他能滑滑板,他可以将篮球投入篮框中。注意这是一个没有眼球的孩子。

第三个例子是触觉皮带,如果你把它戴在腰上,蜂鸣器会响,而且总是朝向北时发出嗡嗡声。它可以使人拥有方向感,用类似于鸟类感知方向的方式。
还有一些离奇的例子:

如果你在青蛙身上插入第三只眼,青蛙也能学会使用那只眼睛。因此,这将会非常令人惊奇。如果你能把几乎任何传感器接入到大脑中,大脑的学习算法就能找出学习数据的方法,并处理这些数据。从某种意义上来说,如果我们能找出大脑的学习算法,然后在计算机上执行大脑学习算法或与之相似的算法,也许这将是我们向人工智能迈进做出的最好的尝试。人工智能的梦想就是:有一天能制造出真正的智能机器。
因此在接下来的一些课程中,我们将开始深入到神经网络的技术细节。
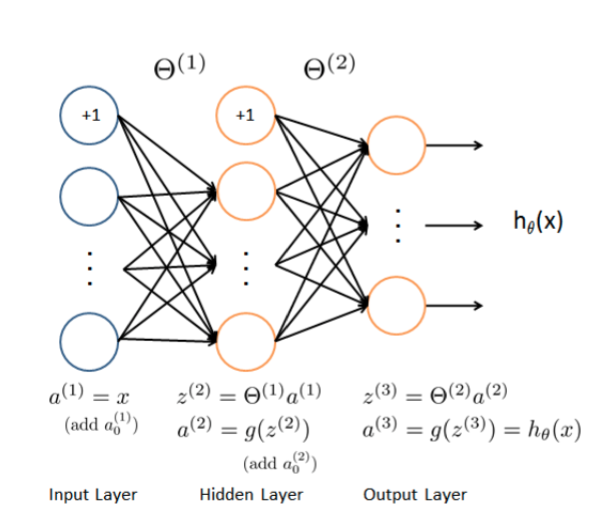
三、神经网络模型 — 前向传播算法
为了构建神经网络模型,我们需要首先思考大脑中的神经网络是怎样的?每一个神经元都可以被认为是一个处理单元/神经核(processing unit/Nucleus),它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。

上面是一组神经元的示意图,神经元利用微弱的电流进行沟通。这些弱电流也称作动作电位,其实就是一些微弱的电流。所以如果神经元想要传递一个消息,它就会就通过它的轴突,发送一段微弱电流给其他神经元.

神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。🚩 这些神经元(也叫激活单元,activation unit)采纳一些特征作为输出,并且根据本身的模型提供一个输出。在神经网络中,参数又可被成为权重(weight)。下图是一个以逻辑回归模型作为自身学习模型的神经元示例:
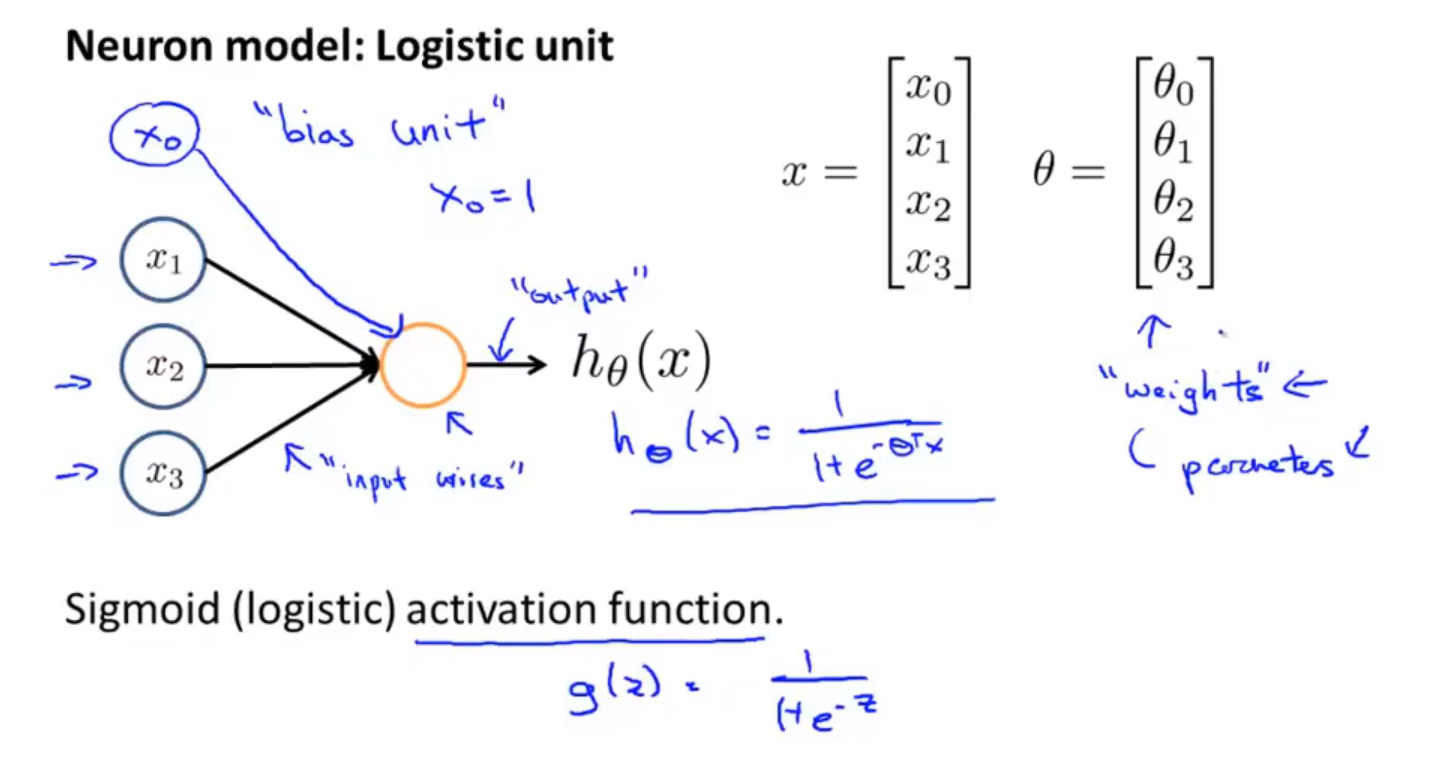
我们设计出了类似于神经元的神经网络,效果如下:

其中, x1 x2 x3是输入单元(input units),我们将原始数据输入给它们。 a1 a2 a3 是中间单元,它们负责将数据进行处理,然后呈递到下一层。 最后是输出单元,它负责计算。
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。上图为一个3层的神经网络,第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)(实际上非输出层和非输入层都称为隐藏层)。我们为每一层都增加一个偏差单位(bias unit):
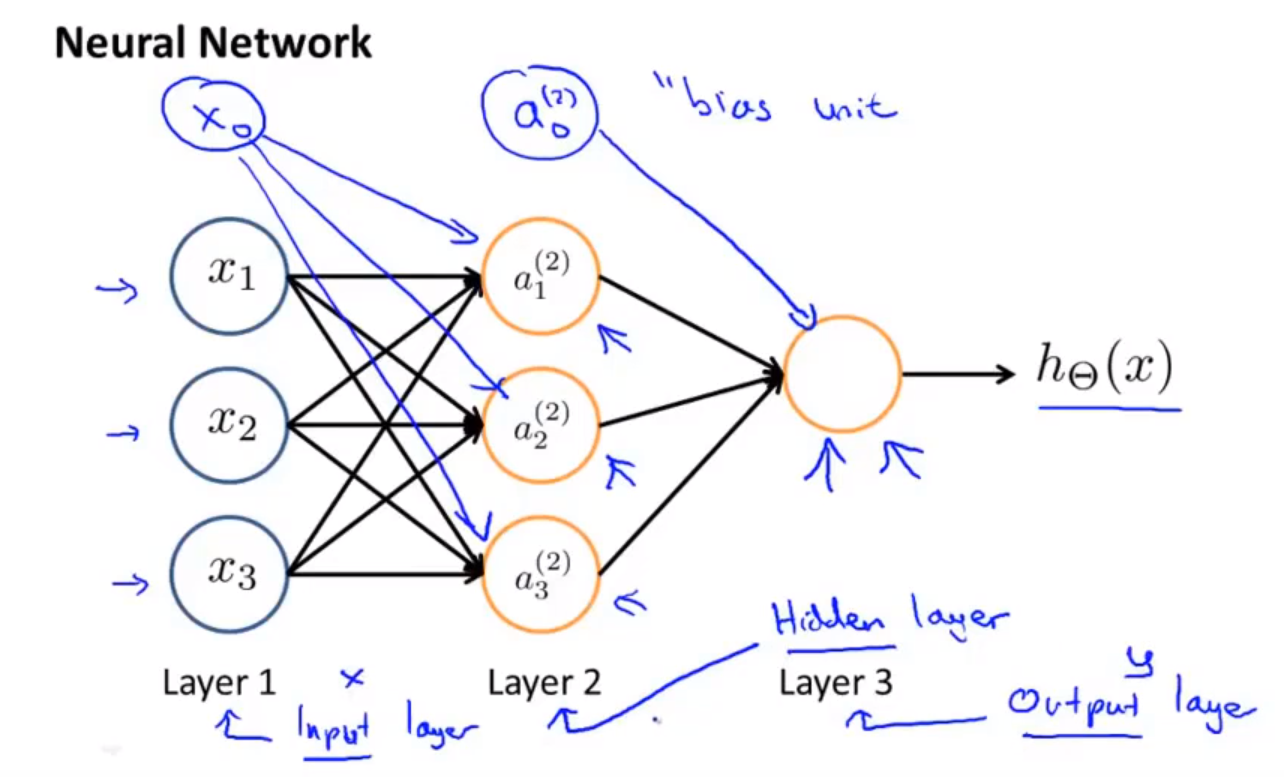
下面引入一些标记法来帮助描述模型:
$a_i^{j}$ :activation of unit i in layer j
代表第 j 层的第 i 个激活单元(所谓激活单元,就是由一个具体神经元计算并输出的值)
$θ^{(j)}$:matrix of weight controlling function mapping from layer j to layer j + 1
代表从第 j 层映射到第 j+1 层时的权重的矩阵,例如 $θ^{(1)}$ 代表从第一层映射到第二层的权重的矩阵
其尺寸为:以第 j+1 层的激活单元数量为行数,以第 j 层的激活单元数加一为列数的矩阵。例如:上图所示的神经网络中 $θ^{(1)}$ 的尺寸为 3*4。
$θ^{1}$ = $θ = \begin{bmatrix} θ^{(1)}_{10} & θ^{(1)}_{11} & θ^{(1)}_{12} & θ^{(1)}_{13} \\ θ^{(1)}_{20} & θ^{(1)}_{21} & θ^{(1)}_{22} & θ^{(1)}_{23} \\ ...\end{bmatrix}$
🚩 $θ^{(1)}_{12}$ 表示 第 1 层到 第 2 层的映射矩阵中,(第 1 层的第 2 个单元) 到 (第 2 层的 第 1 个单元)的映射。(即下标是反向输出的)
🚩 对于上图所示的模型,激活单元和输出分别表达为:
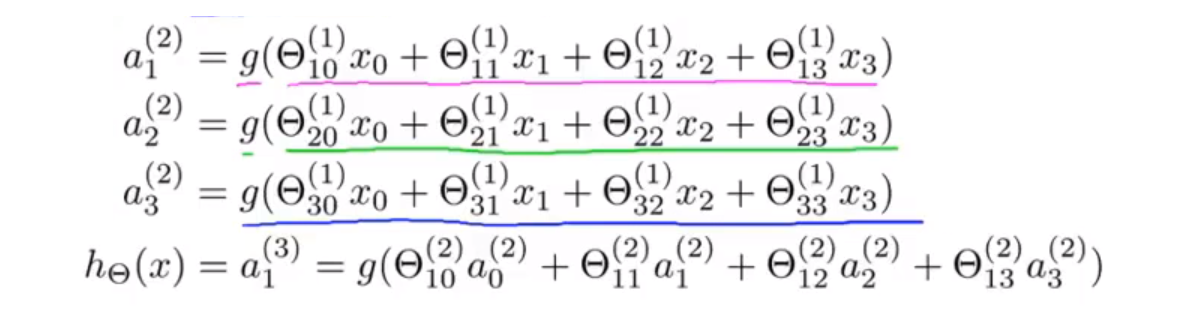
我们可以知道:每一个 a 都是由上一层所有的 x 和每一个 x 所对应的决定的。(⭐ 我们把这样从左到右的算法称为前向传播算法( FORWARD PROPAGATION ))
四、神经网络模型 — 前向传播算法进阶
相对于使用循环来编码,利用向量化的方法会使得计算更为简便。以上面的神经网络为例,试着计算第二层的值:
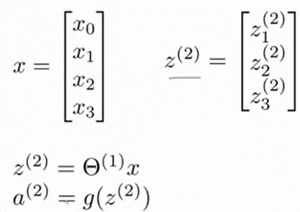

这只是针对训练集中一个训练实例所进行的计算。如果我们要对整个训练集进行计算,我们需要将训练集特征矩阵进行转置,使得同一个实例的特征都在同一列里。即: $z^{(2)} = θ^{(1)} * X^T$
为了更好了了解Neuron Networks的工作原理,我们先把左半部分遮住:
右半部分其实就是以 a0 a1 a2 a3 按照Logistic Regression的方式输出 $h_θ(x)$:
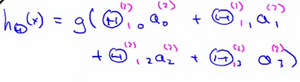
🚩 其实神经网络就像是logistic regression,只不过我们把logistic regression中的输入向量 [x1 ~ x3]变成了中间层的 [ $a_1^{(2)}$ ~ $a_3^{(2)}$], 即: 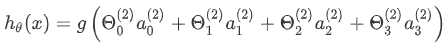 我们可以把 a0 a1 a2 a3 看成更为高级的特征值,也就是 x0 x1 x2 x3 的进化体,并且它们是由 x 与 θ 决定的,因为是梯度下降的,所以 a 是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 x 次方厉害,也能更好的预测新数据。 这就是神经网络相比于逻辑回归和线性回归的优势。
我们可以把 a0 a1 a2 a3 看成更为高级的特征值,也就是 x0 x1 x2 x3 的进化体,并且它们是由 x 与 θ 决定的,因为是梯度下降的,所以 a 是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 x 次方厉害,也能更好的预测新数据。 这就是神经网络相比于逻辑回归和线性回归的优势。
五、例子和直观理解 Examples and Intuitions
从本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用数据中的原始特征 x1 x2 x3 x4 ... xn,我们虽然可以使用一些二项式项来组合这些特征,但是我们仍然受到这些原始特征的限制。在神经网络中,原始特征只是输入层,在我们上面三层的神经网络例子中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。
神经网络中,单层神经元(无中间层)的计算可用来表示逻辑运算,比如逻辑与(AND)、逻辑或(OR)。
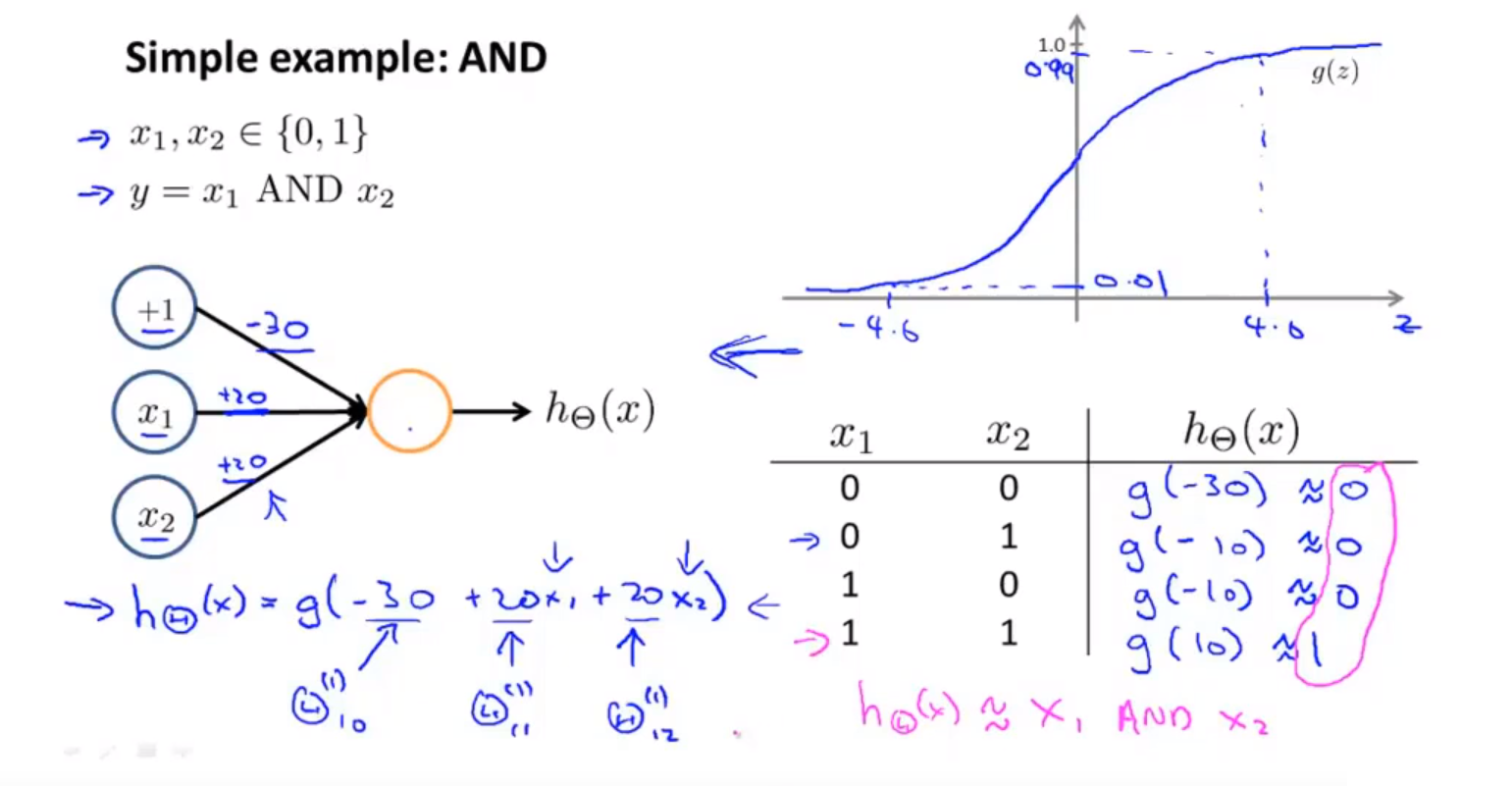
① 神经网络表示 AND 函数
举例说明:用神经网络表现逻辑与(AND)函数;下图中左半部分是神经网络的设计与output层表达式,右边上部分是sigmod函数,下半部分是真值表。
下图的神经元(三个权重分别为-30,20,20)可以被视为作用同于逻辑与(AND):
② 神经网络表示 OR 函数
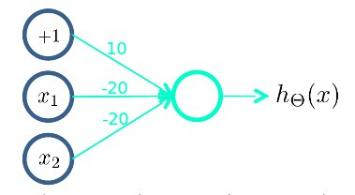
下图的神经元(三个权重分别为-10,20,20)可以被视为作用等同于逻辑或(OR):

OR与AND整体一样,区别只在于的取值不同。
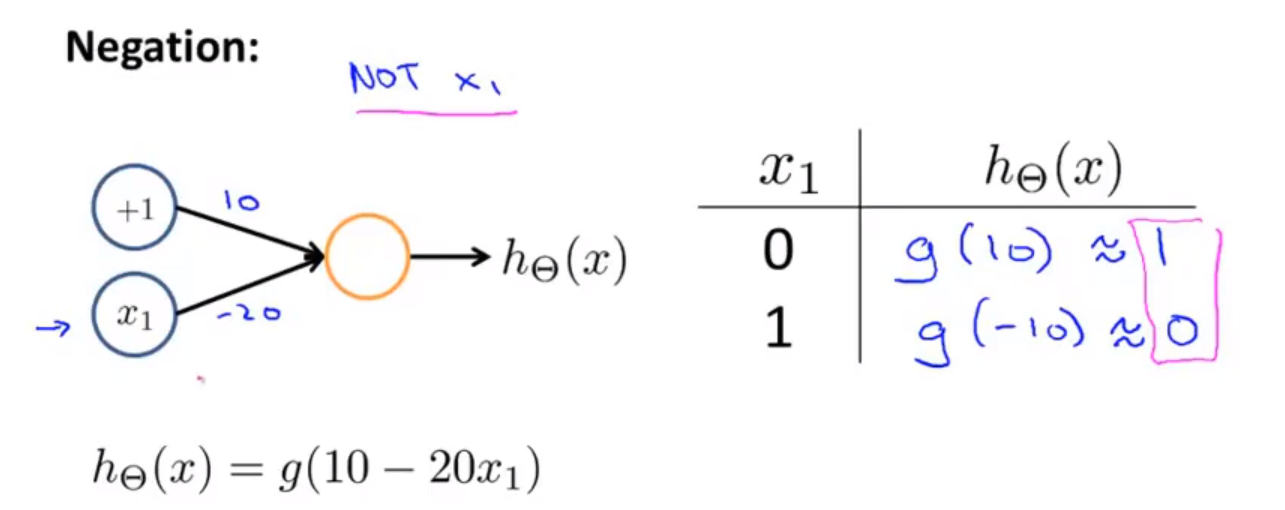
③ 神经网络表示 NOT 函数 逻辑非
下图的神经元(两个权重分别为 10,-20)可以被视为作用等同于逻辑非(NOT):
④ 神经网络表示 XNOR 函数 异或非
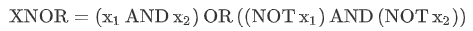
首先构造一个能表达  部分的神经元:
部分的神经元:
然后将表示 的神经元和表示
的神经元和表示 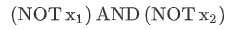 的神经元以及表示 OR 的神经元进行组合:
的神经元以及表示 OR 的神经元进行组合:
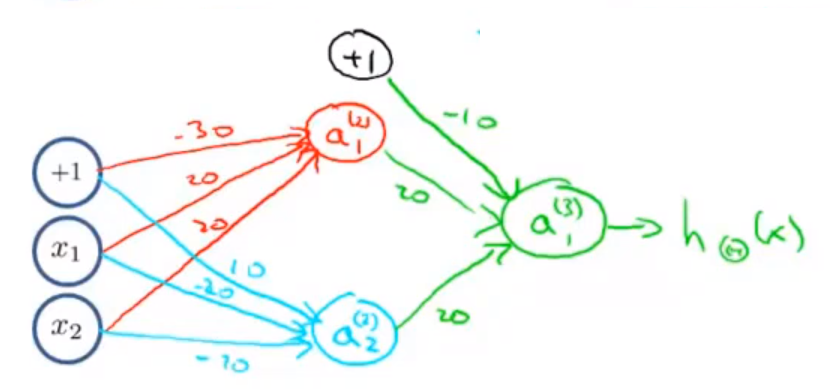
我们就得到了一个能实现 XNOR 运算符功能的神经网络。
按这种方法我们可以逐渐构造出越来越复杂的函数,也能得到更加厉害的特征值。
这就是神经网络的厉害之处。
六、多类别分类 Multiclass Classification
当我们有不止两种分类时(也就是 y = 1, 2, 3...),比如以下这种情况,该怎么办?如果我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有 4 个值。例如,第一个值为 1 或 0 用于预测是否是行人,第二个值用于判断是否为汽车。
输入向量 x 有三个维度,两个中间层,输出层 4 个神经元分别用来表示4类,也就是每一个数据在输出层都会出现 $[a b c d]^T$,且 a b c d 中仅有一个为 1,表示当前类。下面是该神经网络的可能结构示例:
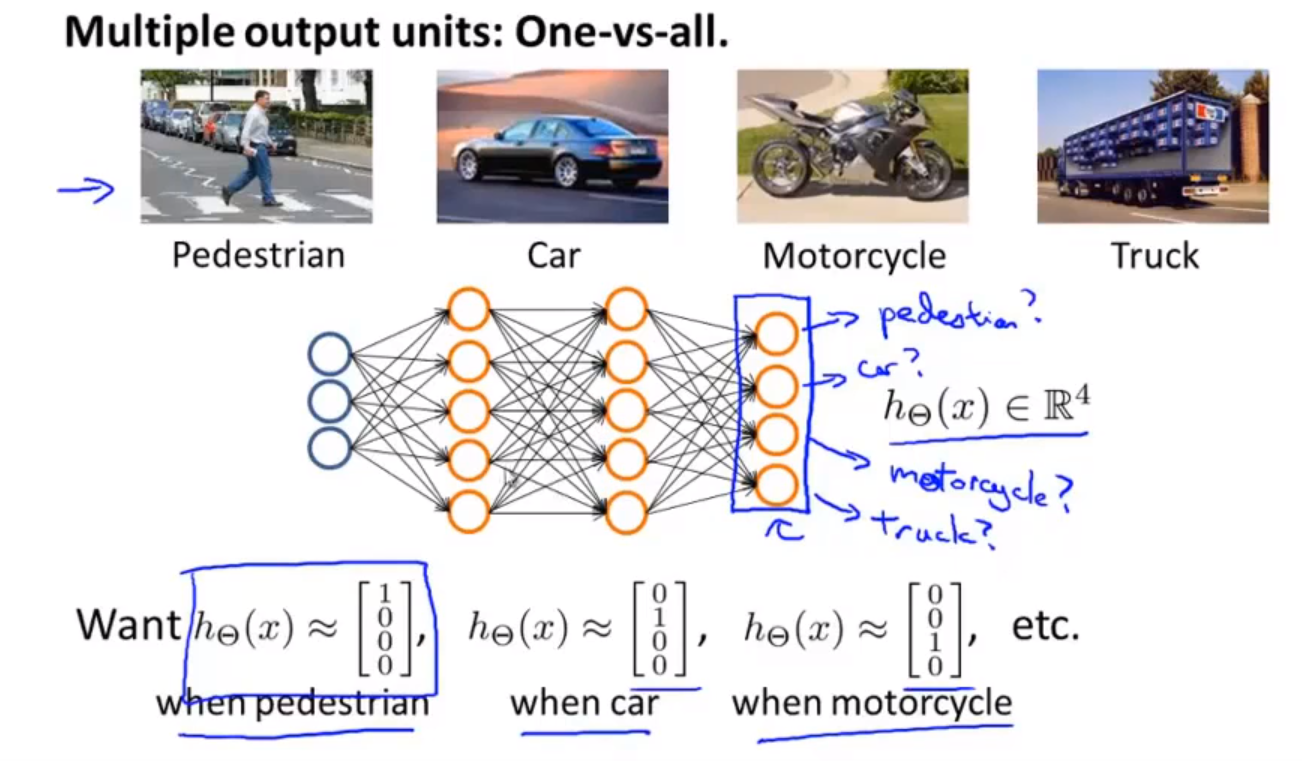
神经网络算法的输出结果为四种可能情形之一:

✍ Quiz
① 第 1 题
以下哪项陈述是正确的?选择所有正确项
✅ 神经网络中隐藏单元的激活值,在应用了sigmoid函数之后,总是在(0,1)范围内
✅ 在二进制值(0或1)上的逻辑函数可以(近似)用一些神经网络来表示
两层(一个输入层,一个输出层,没有隐藏层)神经网络可以表示异或函数
假设有一个三个类的多类分类问题,使用三层网络进行训练。设 $a^{(3)}_1 = (h_\Theta(x))_1$ 为第一输出单元的激活,并且类似地,有 $a^{(3)}_2 = (h_\Theta(x))_2$ 和 $a^{(3)}_3 = (h_\Theta(x))_3$。那么对于任何输入 x,必须有 $a^{(3)}_1 + a^{(3)}_2 + a^{(3)}_3 = 1$
② 第 2 题
考虑以下两个二值输入 x1,x2∈{0,1} 和输出 hΘ(x) 的神经网络。它(近似)计算了下列哪一个逻辑函数?

✅ OR
AND
NAND (与非)
XOR (异或)
③ 第 3 题
考虑下面给出的神经网络。下列哪个方程正确地计算了 $a_1^{(3)}$ 的激活?注:g(z) 是 sigmoid 激活函数
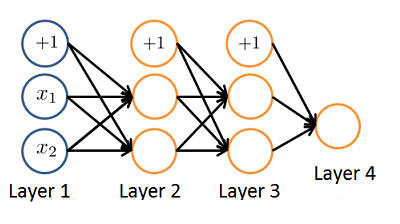
✅ $a_1^{(3)} = g(\Theta_{1,0}^{(2)}a_0^{(2)} + \Theta_{1,1}^{(2)}a_1^{(2)} + \Theta_{1,2}^{(2)}a_2^{(2)})$
$a_1^{(3)} = g(\Theta_{1,0}^{(1)}a_0^{(1)} + \Theta_{1,1}^{(1)}a_1^{(1)} + \Theta_{1,2}^{(1)}a_2^{(1)})$
$a_1^{(3)} = g(\Theta_{1,0}^{(1)}a_0^{(2)} + \Theta_{1,1}^{(1)}a_1^{(2)} + \Theta_{1,2}^{(1)}a_2^{(2)})$
此网络中不存在激活 $a_1^{(3)}$
④ 第 4 题
你有以下神经网络:

你想计算隐藏层 $a^{(2)}∈R^3$ 的激活,一种方法是使用以下 Octave 代码:

您需要一个矢量化的实现(即,一个不用循环的实现)。下列哪个实现正确计算 $a^{(2)}$ ?选出所有正确项
✅ z = Theta1 * x; a2 = sigmoid (z)
a2 = sigmoid (x * Theta1)
a2 = sigmoid (Theta2 * x)
z = sigmoid(x); a2 = sigmoid (Theta1 * z)
⑤ 第 5 题
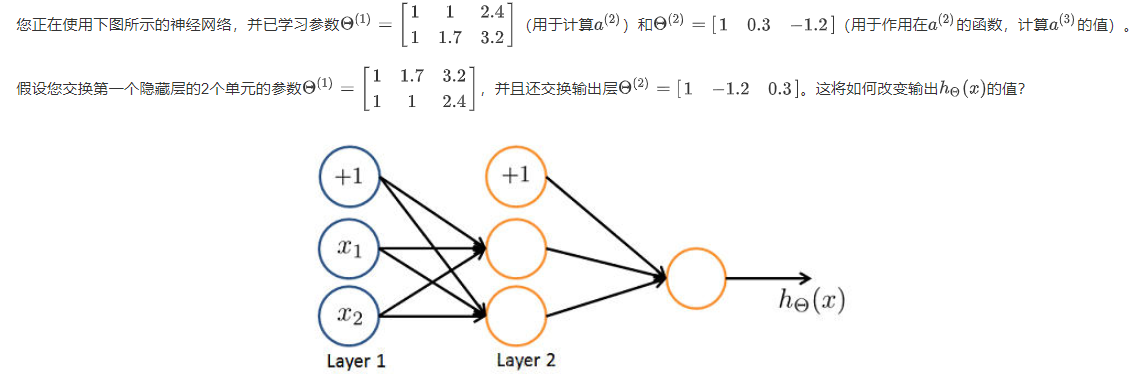
✅ 不变
变大
变小
可能变大也可能变小
原因很简单,原本是 $a_1^{(2)} * -0.2 + a_2^{(2)} * -1.7$,而变化以后,变成了 $a_1^{(2)} * -1.7 + a_2^{(2)} * -0.2$,不过 $a_1^{(2)}$ 和 $a_2^{(2)}$ 也交换了值,所以,结果还是一样的,没有任何改变。
🎳 神经网络:反向传播算法 Neural Networks
一、代价函数 Cost Function
首先引入一些便于稍后讨论的新标记方法:
假设神经网络的训练样本有 m 个,每个包含一组输入 x 和一组输出信号 y ,L 表示神经网络层数,$S_l$ 表示每层的神经元个数(比如 $S_1$ 表示第一层神经元的个数),$S_L$代表最后一层(输出层)中处理单元的个数。
将神经网络的分类定义为两种情况:二类分类和多类分类:
二类分类:$S_L = 1$
K 类分类:$S_L = K (K ≥ 3)$

我们回顾逻辑回归问题中我们的代价函数为:
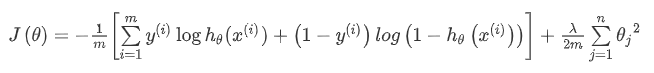
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量 y ,但是在神经网络中,我们可以有很多输出变量,我们的 $h_θ(x)$ 是一个维度为 K 的向量,并且我们训练集中的因变量也是同样维度的一个向量,因此我们的代价函数会比逻辑回归更加复杂一些,为:
⭐ 
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出 K 个预测。🚩 我们可以利用循环,对每一行特征都预测 K 个不同结果,然后在利用循环在 K 个预测中选择可能性最高的一个,将其与 y 中的实际数据进行比较。
二、反向传播算法 Backpropagation Algorithm
🔴 接下来我们学习一种让代价函数最小化的算法:反向传播算法
之前我们在计算神经网络预测结果的时候我们采用了一种前向传播方法,我们从第一层开始正向一层一层进行计算,直到最后一层的 $h_θ(x)$。
现在,为了计算代价函数的偏导数 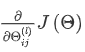 ,我们需要采用一种反向传播算法,也就是 🔴 首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。 以一个例子来说明反向传播算法:
,我们需要采用一种反向传播算法,也就是 🔴 首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。 以一个例子来说明反向传播算法:
假设我们的训练集只有一个样本 (x , y),我们的神经网络是一个四层的神经网络,其中 K = 4,$S_L = 4$,L = 4:
前向传播算法:

反向传播算法:
我们从最后一层的误差开始计算,误差是激活单元的预测($a^{(4)}$)与实际值($y^k$)之间的误差 x。 我们用
δ来表示误差,则:
我们利用这个误差值来计算前一层的误差:
 其中
其中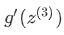 是 Sigmod 函数的导数,
是 Sigmod 函数的导数, 。而
。而 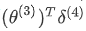 则是权重导致的误差的和。
则是权重导致的误差的和。下一步是继续计算第二层的误差:
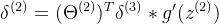
因为第一层是输入变量,不存在误差。我们有了所有的误差的表达式后,便可以计算代价函数的偏导数了,假设,即我们不做任何正则化处理时有:

重要的是清楚地知道上面式子中上下标的含义:
l代表目前所计算的是第几层。j代表目前计算层中的激活单元的下标,也将是下一层的第j个输入变量的下标。i代表下一层中误差单元的下标,是受到权重矩阵中第i行影响的下一层中的误差单元的下标。
在上面的特殊情况中(只有一个训练集),我们需要计算每一层的误差单元来计算代价函数的偏导数。现在 🚩 我们将其推广到具有 m 个训练集的情况:我们同样需要计算每一层的误差单元,但是我们需要为整个训练集计算误差单元,此时的误差单元也是一个矩阵,我们用 $△_{ij}^{(l)}$ 来表示这个误差矩阵。第 l 层的第 i 个激活单元受到第 j 个参数影响而导致的误差。
我们的算法表示为:

⭐ 即首先用正向传播方法计算出每一层的激活单元,利用训练集的结果与神经网络预测的结果求出最后一层的误差,然后利用该误差运用反向传播法计算出直至第二层的所有误差。
在求出了 $△_{ij}^{(l)}$ 之后,我们便可以计算 ⭐ 代价函数的偏导数了,计算方法如下:

三、BP算法的直观理解 Backpropagation Intuition
为了更好地理解反向传播算法,我们再来仔细研究一下前向传播的原理:
前向传播算法:

反向传播算法:

四、BP算法的实现细节:展开参数 Implementation Note_ Unrolling Parameters
在上一段视频中,我们谈到了怎样使用反向传播算法计算代价函数的导数。在这段视频中,我想快速地向你介绍一个细节的实现过程,怎样把你的参数从矩阵展开成向量,以便我们在高级最优化步骤中的使用需要。


五、梯度检验 Gradient Checking
当我们对一个较为复杂的模型(例如神经网络)使用梯度下降算法时,可能会存在一些不容易察觉的错误,意味着,虽然代价看上去在不断减小,但最终的结果可能并不是最优解。(大部分原因都是 BP 算法自身的 Bug)
为了避免这样的问题,我们采取一种叫做梯度的数值检验(Numerical Gradient Checking)方法。这种方法的思想是通过估计梯度值来检验我们计算的导数值是否真的是我们要求的。
对梯度的估计采用的方法是在代价函数上沿着切线的方向选择离两个非常近的点然后计算两个点的平均值用以估计梯度。即对于某个特定的 θ,我们计算出在 θ-ε 处和 θ+ε 的代价值(ε 是一个非常小的值,通常选取 0.0001),然后求两个代价的平均,用以估计在 θ 处的代价值。
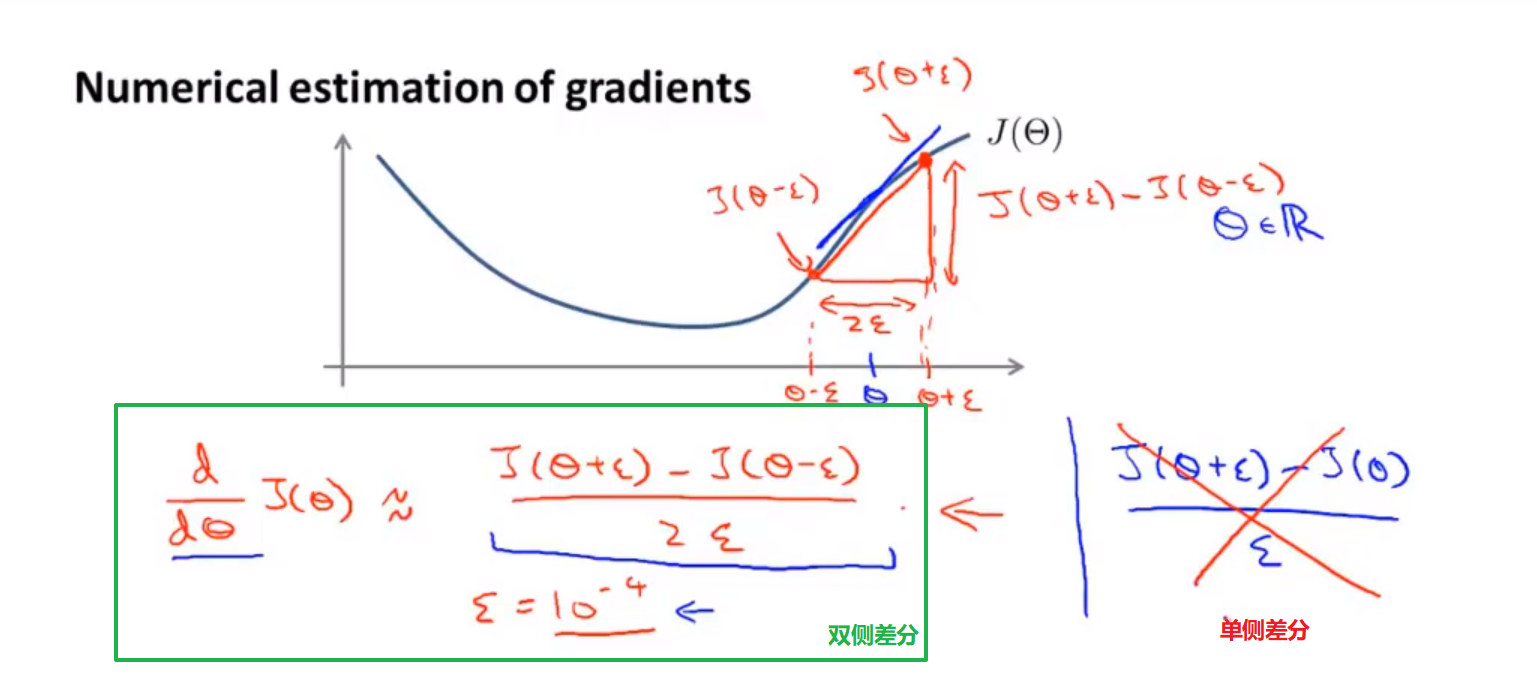
当是一个向量时,我们则需要对偏导数进行检验。因为代价函数的偏导数检验只针对一个参数的改变进行检验:

🚨 在运行你的代码进行学习或者说训练网络之前,务必关掉梯度检验。因为梯度检验的代码是一个计算量非常大的,也是非常慢的计算导数的程序。而 BP 算法是一个高性能的计算导数的方法,一旦你通过梯度校验证明反向传播的实现是正确的,就应该关掉梯度校验。
六、随机初始化 Random Initialization
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为 0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为同一个非 0 的数,结果也是一样的。
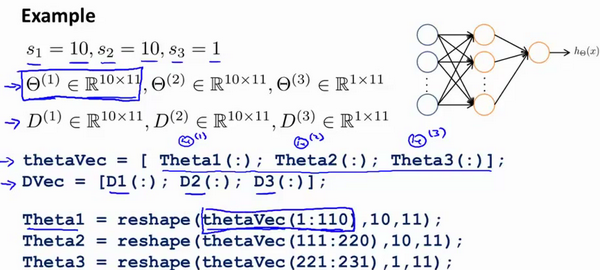
🚩 我们通常初始参数为正负 ε (这里的 ε 和梯度校验的 ε 没有任何关系 )之间的随机值,假设我们要随机初始一个尺寸为 10×11 的参数矩阵,代码如下:

七、小结 Putting It Together
总结一下使用神经网络时的步骤:
第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。

第一层的单元数即我们训练集的特征数量。
最后一层的单元数是我们训练集的结果的类的数量。
如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
接下来就是训练神经网络:
参数的随机初始化
利用正向传播方法计算所有的 $h_θ(x)$
编写计算代价函数 J 的代码
利用反向传播方法计算所有偏导数
利用梯度检验方法检验这些偏导数
使用优化算法(比如梯度下降算法或者更高级的优化方法)来最小化代价函数
🚨 神经网络中的代价函数是非凸函数,也就是说梯度下降算法或者其他更高级的优化方法得到的都有可能只是局部最小值,但这不是个大问题,因为这些算法在一般情况下都能得到一个比较小的局部最小值,尽管它可能不是全局最小值
✍ Quiz
① 第 1 题
您正在训练一个三层神经网络,希望使用反向传播来计算代价函数的梯度。 在反向传播算法中,其中一个步骤是更新 $\Delta^{(2)}_{ij} := \Delta^{(2)}_{ij} + \delta^{(3)}_i * (a^{(2)})_j$ 对于每个i,j,下面哪一个是这个步骤的正确矢量化?
$\Delta^{(2)} := \Delta^{(2)} + (a^{(2)})^T * \delta^{(3)}$
$\Delta^{(2)} := \Delta^{(2)} + (a^{(3)})^T * \delta^{(2)}$
✅ $\Delta^{(2)} := \Delta^{(2)} + \delta^{(3)} * (a^{(2)})^T$
$\Delta^{(2)} := \Delta^{(2)} + \delta^{(3)} * (a^{(3)})^T$
② 第 2 题
假设Theta1是一个 5x3 矩阵,Theta2是一个 4x6 矩阵。令thetaVec=[Theta1(;);Theta2(:)]。下列哪一项可以正确地还原Theta2?
✅
reshape(thetaVec(16:39),4,6)5x3 + 4x6 = 39
reshape(thetaVec(15:38),4,6)reshape(thetaVec(16:24),4,6)reshape(thetaVec(15:39),4,6)reshape(thetaVec(16:39),6,4)
③ 第 3 题

8
6
5.9998
✅ 6.0002
④ 第 4 题
以下哪项陈述是正确的?选择所有正确项
使用较大的 λ 值不会影响神经网络的性能;我们不将 λ 设置为太大的唯一原因是避免数值问题
如果我们使用梯度下降作为优化算法,梯度检查是有用的。然而,如果我们使用一种先进的优化方法(例如在fminunc中),它没有多大用处
✅ 使用梯度检查可以帮助验证反向传播的实现是否没有 bug
✅ 如果我们的神经网络过拟合训练集,一个合理的步骤是增加正则化参数 λ
⑤ 第 5 题
以下哪项陈述是正确的?选择所有正确项
假设参数$Θ^{(1)}$是一个方矩阵(即行数等于列数)。如果我们用它的转置代${Θ^{(1)}}^T$替$Θ^{(1)}$,那么我们并没有改变网络正在计算的功能。
✅ 假设我们有一个正确的反向传播实现,并且正在使用梯度下降训练一个神经网络。假设我们将 J(Θ) 绘制为迭代次数的函数,并且发现它是递增的而不是递减的。一个可能的原因是学习率 α 太大。
假设我们使用学习率为 α 的梯度下降。对于逻辑回归和线性回归,J(Θ) 是一个凸优化问题,因此我们不想选择过大的学习率 α。 然而,对于神经网络,J(Θ)可能不是凸的,因此选择一个非常大的 α 值只能加快收敛速度。
✅ 如果我们使用梯度下降训练一个神经网络,一个合理的调试步骤是将 J(Θ) 绘制为迭代次数的函数,并确保每次迭代后它是递减的(或至少是不递增的)。
