🍭 大规模机器学习(Large Scale Machine Learning)
一、大型数据集的学习 Learning With Large Datasets
如果我们有一个低方差的模型,增加数据集的规模可以帮助你获得更好的结果。我们应该怎样应对一个有100万条记录的训练集?
以线性回归模型为例,每一次梯度下降迭代,我们都需要计算训练集的误差的平方和,如果我们的学习算法需要有20次迭代,这便已经是非常大的计算代价。
首先应该做的事是去检查一个这么大规模的训练集是否真的必要,也许我们只用1000个训练集也能获得较好的效果,我们可以绘制学习曲线来帮助判断。
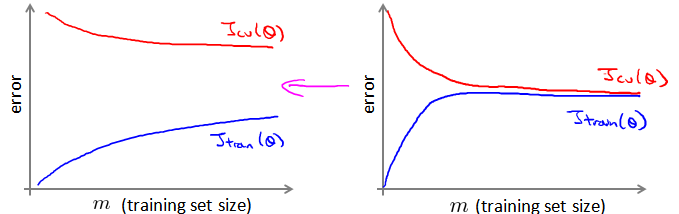
上图左边是高方差模型,显然增加数据集能够提升算法效果。上图右边是高偏差模型,增加数据集并没有什么显著的效果。
二、随机梯度下降法 Stochastic Gradient Descent
如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法来代替批量梯度下降法。
💡 批量梯度下降法回顾:

在随机梯度下降法中,我们不需要每次迭代都考虑全部的训练样本,仅仅只需要考虑一个训练样本:
$$cost \left( \theta, \left( {x}^{(i)} , {y}^{(i)} \right) \right) = \frac{1}{2}\left( {h}_{\theta}\left({x}^{(i)}\right)-{y}^{{(i)}} \right)^{2}$$
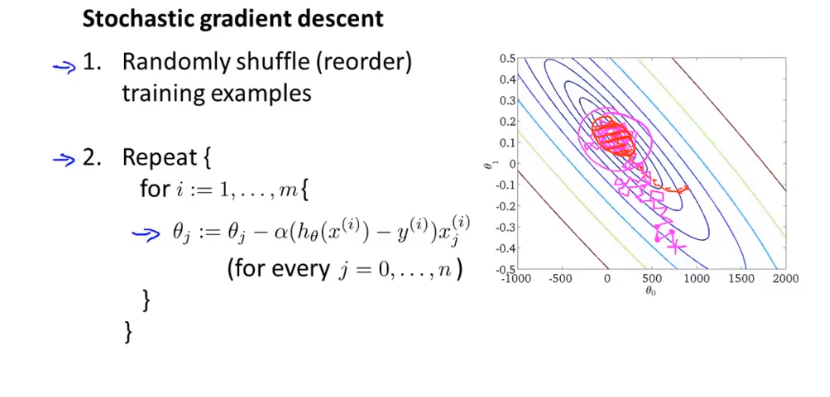
🔴 随机梯度下降算法为:首先对训练集随机“洗牌”,然后:
Repeat (usually anywhere between1-10){
for $i = 1:m${
$\theta:={\theta}_{j}-\alpha\left( {h}_{\theta}\left({x}^{(i)}\right)-{y}^{(i)} \right){{x}_{j}}^{(i)}$
(for $j=0:n$)
}
}
⭐ 随机梯度下降算法在每一次计算之后便更新参数 ${{\theta }}$ ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存在的问题是,不是每一步都是朝着”正确”的方向迈出的。因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。
三、小批量梯度下降 Mini-Batch Gradient Descent
小批量梯度下降算法 Mini-Batch 是介于批量梯度下降算法和随机梯度下降算法之间的算法,🚩 每计算常数$b$次训练实例,便更新一次参数 ${{\theta }}$ 。 通常我们会令 $b$ 在 2-100 之间。

这样做的好处在于,我们可以用向量化的方式来循环 $b$个训练实例,如果我们用的线性代数函数库比较好,能够支持平行处理,那么算法的总体表现将不受影响(与随机梯度下降相同)。
四、随机梯度下降收敛 Stochastic Gradient Descent Convergence
现在我们介绍随机梯度下降算法的调试,以及学习率 $α$ 的选取。
在批量梯度下降中,我们可以令代价函数$J$为迭代次数的函数,绘制图表,根据图表来判断梯度下降是否收敛。但是,在大规模的训练集的情况下,这是不现实的,因为计算代价太大了。
🚩 在随机梯度下降中,我们在每一次更新 ${{\theta }}$ 之前都计算一次代价,然后每 $x$ 次迭代后,求出这$x$次对训练实例计算代价的平均值,然后绘制这些平均值与 $x$ 次迭代的次数之间的函数图表。
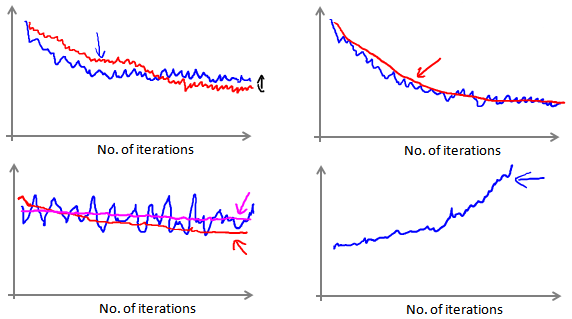
当我们绘制这样的图表时,可能会得到一个颠簸不平但是不会明显减少的函数图像(如上面左下图中蓝线所示)。我们可以增加$α$来使得函数更加平缓,也许便能看出下降的趋势了(如上面左下图中红线所示);或者可能函数图表仍然是颠簸不平且不下降的(如洋红色线所示),那么我们的模型本身可能存在一些错误。
如果我们得到的曲线如上面右下方所示,不断地上升,那么我们可能会需要选择一个较小的学习率$α$。
我们也可以令学习率随着迭代次数的增加而减小,例如令:
$$\ alpha = \frac{const1}{iterationNumber + const2}$$
随着我们不断地靠近全局最小值,通过减小学习率,我们迫使算法收敛而非在最小值附近徘徊。 但是通常我们不需要这样做便能有非常好的效果了,对$α$进行调整所耗费的计算通常不值得
🚩 总结下,本节我们介绍了一种方法,近似地监测出随机梯度下降算法在最优化代价函数中的表现,这种方法不需要定时地扫描整个训练集,来算出整个样本集的代价函数,而是只需要每次对最后1000个或者多少个样本,求一下平均值。应用这种方法,你既可以保证随机梯度下降法正在正常运转和收敛,也可以用它来调整学习速率$α$的大小。
五、在线学习 Online Learning
本节我们讨论一种新的大规模的机器学习机制,叫做在线学习机制。在线学习机制让我们可以模型化问题。
今天,许多大型网站或者许多大型网络公司,使用不同版本的在线学习机制算法,从大批的涌入又离开网站的用户身上进行学习。特别要提及的是,如果你有一个由连续的用户流引发的连续的数据流,进入你的网站,你能做的是使用一个在线学习机制,从数据流中学习用户的偏好,然后使用这些信息来优化一些关于网站的决策。
假定你有一个提供运输服务的公司,用户们来向你询问把包裹从A地运到B地的服务,同时假定你有一个网站,让用户们可多次登陆,然后他们告诉你,他们想从哪里寄出包裹,以及包裹要寄到哪里去,也就是出发地与目的地,然后你的网站开出运输包裹的的服务价格。比如,我会收取$50来运输你的包裹,我会收取$20之类的,然后根据你开给用户的这个价格,用户有时会接受这个运输服务,那么这就是个正样本,有时他们会走掉,然后他们拒绝购买你的运输服务,所以,让我们假定我们想要一个学习算法来帮助我们,优化我们想给用户开出的价格。
在线学习算法指的是对数据流而非离线的静态数据集的学习。许多在线网站都有持续不断的用户流,对于每一个用户,🔴 网站希望能在不将数据存储到数据库中便顺利地进行算法学习。
假使我们正在经营一家物流公司,每当一个用户询问从地点A至地点B的快递费用时,我们给用户一个报价,该用户可能选择接受($y=1$)或不接受($y=0$)。
现在,我们希望构建一个模型,来预测用户接受报价使用我们的物流服务的可能性。因此报价 是我们的一个特征,其他特征为距离,起始地点,目标地点以及特定的用户数据。模型的输出是:$p(y=1)$。
在线学习的算法与随机梯度下降算法有些类似,我们对单一的实例进行学习,而非对一个提前定义的训练集进行循环。
Repeat forever (as long as the website is running) {
Get $\left(x,y\right)$ corresponding to the current user
$\theta:={\theta}_{j}-\alpha\left( {h}_{\theta}\left({x}\right)-{y} \right){{x}_{j}}$ ($j=0:n$)
}
一旦对一个数据的学习完成了,我们便可以丢弃该数据,不需要再存储它了。这种方式的好处在于,我们的算法可以很好的适应用户的倾向性,算法可以针对用户的当前行为不断地更新模型以适应该用户。
每次交互事件并不只产生一个数据集,例如,我们一次给用户提供3个物流选项,用户选择2项,我们实际上可以获得3个新的训练实例,因而我们的算法可以一次从3个实例中学习并更新模型。
这些问题中的任何一个都可以被归类到标准的,拥有一个固定的样本集的机器学习问题中。或许,你可以运行一个你自己的网站,尝试运行几天,然后保存一个数据集,一个固定的数据集,然后对其运行一个学习算法。但是这些是实际的问题,在这些问题里,你会看到大公司会获取如此多的数据,真的没有必要来保存一个固定的数据集,取而代之的是你可以使用一个在线学习算法来连续的学习,从这些用户不断产生的数据中来学习。这就是在线学习机制,与随机梯度下降算法非常类似,唯一的区别的是,我们不会使用一个固定的数据集,我们会做的是获取一个用户样本,从那个样本中学习,然后丢弃那个样本并继续下去,而且如果你对某一种应用有一个连续的数据流,这样的算法可能会非常值得考虑。当然,在线学习的一个优点就是,如果你有一个变化的用户群,又或者你在尝试预测的事情,在缓慢变化,就像你的用户的品味在缓慢变化,这个在线学习算法,可以慢慢地调试你所学习到的假设,将其调节更新到最新的用户行为。
六、映射化简和数据并行 Map Reduce and Data Parallelism
映射化简和数据并行 对于大规模机器学习问题而言是非常重要的概念。之前提到,如果我们用批量梯度下降算法来求解大规模数据集的最优解,我们需要对整个训练集进行循环,计算偏导数和代价,再求和,计算代价非常大。🔴 如果我们能够将我们的数据集分配给多台计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样的方法叫做映射简化。
具体而言,如果任何学习算法能够表达为,对训练集的函数的求和,那么便能将这个任务分配给多台计算机(或者同一台计算机的不同CPU 核心),以达到加速处理的目的。
例如,我们有400个训练实例,我们可以将批量梯度下降的求和任务分配给4台计算机进行处理:

很多高级的线性代数函数库已经能够利用多核CPU的多个核心来并行地处理矩阵运算,这也是算法的向量化实现如此重要的缘故(比调用循环快)。
✍ Quiz
① 第 1 题
假设您正在使用随机梯度下降训练逻辑回归分类器。你发现在过去的500个例子中,成本(即 $cost(\theta,(x^{(i)}, y^{(i)}))$ ,500个例子平均后)绘制为迭代次数的函数,随时间缓慢增加。以下哪项更改可能有帮助?
试着在图中用较少的例子(比如250个例子而不是500个)来计算平均成本。
这在随机梯度下降的情况下是不可能的,因为它保证收敛到最优参数θ。
✅ 尝试将学习率α减半(减少),看看这是否会导致成本持续下降;如果没有,继续减半直到成本会持续下降。
从训练集中取更少的例子
② 第 2 题
下列关于随机梯度下降的陈述哪一个是正确的?选出所有正确项
✅ 您可以使用数值梯度检查的方法来验证您的随机梯度下降实现是对的(随机梯度下降自重一步是计算偏导数 $\frac{\partial}{\partial \theta_j} cost(\theta, (x^{(i)}, y^{(i)}))$ )
✅ 在运行随机梯度下降之前,您应该随机洗牌(重新排序)训练集。
假设您使用随机梯度下降来训练线性回归分类器。代价函数 $J(\theta) = \frac{1}{2m} \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})^2$ 一定会随着每次迭代减小。
为了确保随机梯度下降收敛,我们通常在每次迭代后计算 $J_{\rm train}(\theta)$ ,并绘制它,以确保成本函数总体上是递减的。
③ 第 3 题
以下关于在线学习的陈述哪一个是正确的?选出所有正确项
✅ 如果我们有一个连续/不间断的数据流,用在线学习算法通常是最适合的。
当我们有一个大小为m的固定训练集需要训练时,在线学习算法是最合适的。
使用在线学习时,您必须保存获得的每个新培训示例,因为您将需要重用过去的示例来重新训练模型,即使在将来获得新的训练例子之后也是如此。
✅ 在线学习的一个优点是,如果我们正在建模的功能随着时间的推移而变化(例如,如果我们正在建模用户单击不同URL的概率,并且用户的品味/偏好随着时间的推移而变化),在线学习算法将自动适应这些变化。
④ 第 4 题
假设您有一个非常大的训练集,您认为以下哪种算法可以使用 map-reduce 和跨不同机器拆分训练集来并行化?选出所有正确项
用随机梯度下降训练逻辑回归
用随机梯度下降训练线性回归
✅ 用批量梯度下降训练逻辑回归
✅ 计算训练集中所有特征的平均值 $\mu = \frac{1}{m} \sum_{i=1}^m x^{(i)}$(例如为了执行平均归一化)
⑤ 第 5 题
下面关于 map-reduce 的哪些语句是正确的?选出所有正确项
✅ 由于网络延迟和其他与map-reduce相关的开销,如果我们使用N台计算机运行map-reduce,与使用1台计算机相比,我们可能会得到小于N倍的加速。
✅ 如果您只有一台具有一个计算核心的计算机,那么map-reduce不太可能有帮助。
✅ 当使用带梯度下降的 map-reduce 时,我们通常使用一台机器从每个 map-reduce 机器中累积梯度,以便计算该迭代的参数更新。
线性回归和逻辑回归可以用 map-reduce 并行化,但神经网络训练不能。
💡 神经网络也要计算代价函数也要有大量计算,所以神经网络也可以并行计算。
🍡 应用实例:图片文字识别(Application Example: Photo OCR)
一、问题描述和流程图
像文字识别应用所作的事是,从一张给定的图片中识别文字。这比从一份扫描文档中识别文字要复杂的多。

为了完成这样的工作,需要采取如下步骤:
文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
字符切分(Character segmentation)——将文字分割成一个个单一的字符
字符分类(Character classification)——确定每一个字符是什么 可以用任务流程图来表达这个问题,每一项任务可以由一个单独的小队来负责解决:

二、滑动窗口 Sliding Windows
滑动窗口是一项用来从图像中抽取对象的技术。假使我们需要在一张图片中识别行人,首先要做的是用许多固定尺寸的图片来训练一个能够准确识别行人的模型。然后我们用之前训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁,然后将剪裁得到的切片交给模型,让模型判断是否为行人,然后在图片上滑动剪裁区域重新进行剪裁,将新剪裁的切片也交给模型进行判断,如此循环直至将图片全部检测完。
一旦完成后,我们按比例放大剪裁的区域,再以新的尺寸对图片进行剪裁,将新剪裁的切片按比例缩小至模型所采纳的尺寸,交给模型进行判断,如此循环。

滑动窗口技术也被用于文字识别,首先训练模型能够区分字符与非字符,然后,运用滑动窗口技术识别字符,一旦完成了字符的识别,我们将识别得出的区域进行一些扩展,然后将重叠的区域进行合并。接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(认为单词的长度通常比高度要大)。下图中绿色的区域是经过这些步骤后被认为是文字的区域,而红色的区域是被忽略的。
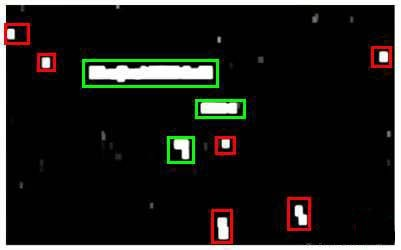
以上便是文字侦测阶段。 下一步是训练一个模型来完成将文字分割成一个个字符的任务,需要的训练集由单个字符的图片和两个相连字符之间的图片来训练模型。
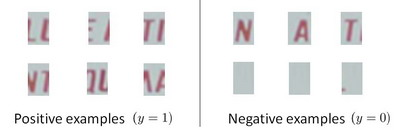
模型训练完后,我们仍然是使用滑动窗口技术来进行字符识别。

以上便是字符切分阶段。 最后一个阶段是字符分类阶段,利用神经网络、支持向量机或者逻辑回归算法训练一个分类器即可。
三、获取大量数据和人工数据
如果我们的模型是低方差的,那么获得更多的数据用于训练模型,是能够有更好的效果的。问题在于,我们怎样获得数据,数据不总是可以直接获得的,我们有可能需要人工地创造一些数据。
以我们的文字识别应用为例,我们可以字体网站下载各种字体,然后利用这些不同的字体配上各种不同的随机背景图片创造出一些用于训练的实例,这让我们能够获得一个无限大的训练集。这是从零开始创造实例。
另一种方法是,利用已有的数据,然后对其进行修改,例如将已有的字符图片进行一些扭曲、旋转、模糊处理。只要我们认为实际数据有可能和经过这样处理后的数据类似,我们便可以用这样的方法来创造大量的数据。
有关获得更多数据的几种方法:
人工数据合成
手动收集、标记数据
众包
四、上限分析:哪部分最值得花时间去改善 Ceiling Analysis
❓ 在机器学习的应用中,我们通常需要通过几个步骤才能进行最终的预测,我们如何能够知道哪一部分最值得我们花时间和精力去改善呢?这个问题可以通过上限分析来回答。
回到我们的文字识别应用中,我们的流程图如下:

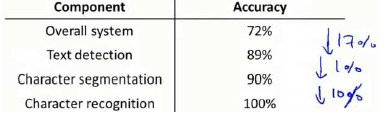
流程图中每一部分的输出都是下一部分的输入,上限分析中,我们选取一部分,手工提供100%正确的输出结果,然后看应用的整体效果提升了多少。假使我们的例子中总体效果为72%的正确率。
如果我们令文字侦测部分输出的结果100%正确,发现系统的总体效果从72%提高到了89%。这意味着我们很可能会希望投入时间精力来提高我们的文字侦测部分。
接着我们手动选择数据,让字符切分输出的结果100%正确,发现系统的总体效果由 89% 只提升了1%,这意味着,我们的字符切分部分可能已经足够好了。
最后我们手工选择数据,让字符分类输出的结果100%正确,系统的总体效果从 90% 又提升了10%,这意味着我们可能也会应该投入更多的时间和精力来提高应用的总体表现。
✍ Quiz
① 第 1 题
假设您正在运行一个滑动窗口检测器来查找图像中的文本。您的输入图像为1000x1000像素。你将在两个尺寸下运行你的滑动窗口探测器,10x10和20x20(即,您将在大量10x10的窗口上运行分类器,以确定它们是否包含文本;同样的,也在20x20的窗口上),你将每次滑动你的探测器2像素。 那么,在单张1000x1000的测试图像上,运行分类器的次数是多少?
✅ 500,000
1,000,000
100,000
250,000
💡 $1000*1000$大小,每次移动步长2像素,所以总共是 $500* 500=250000$ 次滑动,两个就是500000次滑动
② 第 2 题
假设您刚刚加入了一个产品团队,该团队使用训练数据开发了一个机器学习应用程序。您发现您可以选择雇用其他人员来帮助收集和标记数据。 你估计你得给每个标记工每小时10美元,每个标记工每分钟可以标记4个样本。 雇佣标记工给10000个新的训练数据打标签要花多少钱?
✅ 400
600
250
10,000
③ 第 3 题
进行上限分析有什么好处?选出所有正确项
这是为算法提供额外训练数据的一种方法。
✅ 使用上限分析能帮助我们分析流水线的哪个部分对整个系统的提高最大。
✅ 使用上限分析能让我们知道到某个模块需不需要花精力做好;因为就算把这个模块精度提高到100%了,也无助于提高整个系统的精度。
使用上限分析并不会帮我们分析出哪个部分是 high bias,哪个部分是 high variance。
④ 第 4 题
假设您正在构建一个对象分类器,它将图像作为输入,并将该图像识别为包含汽车(y=1y=1)或不包含汽车(y=0y=0)。例如,这里有正例和一个负例:

在仔细分析了算法的性能之后,你的结论是你需要更多正例(y=1)。下面哪一个可能是获得更多正面例子的好方法?
✅ 对现有训练集中的图像应用平移、扭曲和旋转。
选择两个汽车图像并对其进行平均以生成第三个示例。
从训练集中获取一些图像,并向每个像素添加随机高斯噪声。
为训练集中的每个图像制作两份副本;这会立即使训练集大小加倍。
⑤ 第 5 题
假设您有一个图片手写字符识别系统,其中有以下流水线:

您已决定对此系统执行上限分析,并得到以下内容:

以下哪项陈述是正确的?
✅ Text Detection 提高得效果不明显,因此没有必要花费大量时间去改善它
✅ 如果 Character Recognition 的错误是由系统的高方差引起的,那么我们继续提供大量的数据是非常有效的
最没有前途的部分是 Character Recognition,因为它已经获得了100%的准确率。
最有前途的组件是 Text Detection,因为它的性能最低(72%),因此潜在增益最大。
