聚类在输入为多个数据时,将“相似”的数据分为一组的操作,1个组就叫作1个“簇”。
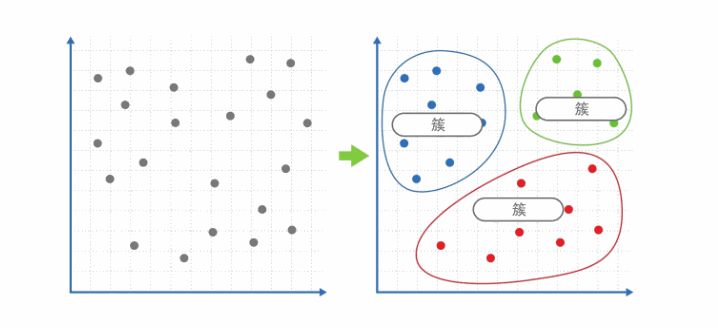
如何定义相似定义数据间的差距,使用用最具代表性的聚类算法“k-means算法”。该算法可以把数据按要求分为k个簇。
k-means算法它可以根据事先给定的簇的数量进行聚类。
「流程」
首先准备好需要聚类的数据,然后决定簇的数量。本例中我们将簇的数量定为3。此处用点表示数据,用两点间的直线距离表示数据间的差距。
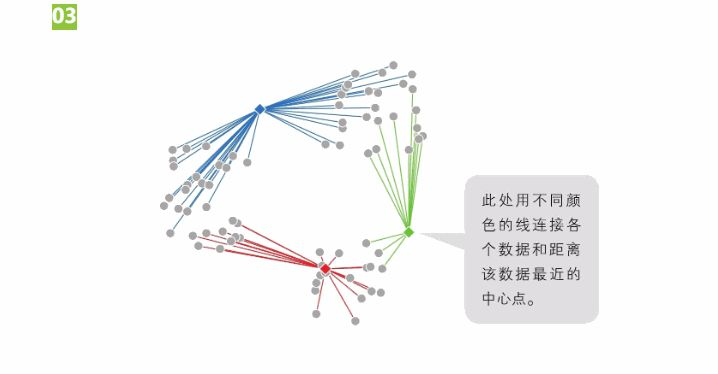
随机选择3个点作为簇的中心点。计算各个数据分别和3个中心点中的哪一个点距离最近。
将数据分到相应的簇中。这样,3个簇的聚类就完成了。
计算各个簇中数据的重心,然后将簇的中心点移动到这个位置。
重新计算距离最近的簇的中心点,并将数据分到相应的簇中。
重复执行“将数据分到相应的簇中”和“将中心点移到重心的位置”这两个操作,直到中心点不再发生变化为止。操作到此结束,聚类也就完成了
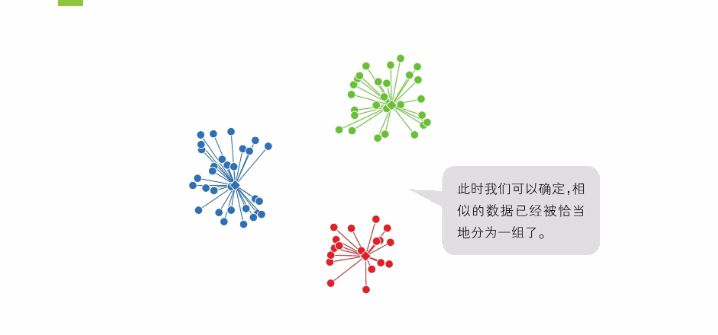
特点k-means算法中,随着操作的不断重复,中心点的位置必定会在某处收敛,这一点已经在数学层面上得到证明。
层次聚类算法不需要事先设定簇的数量,一开始每个数据都自成一类。也就是说,有n个数据就会形成n个簇。然后重复执行“将距离最近的两个簇合并为一个”的操作n-1次。每执行1次,簇就会减少1个。执行n-1次后,所有数据就都被分到了一个簇中。在这个过程中,每个阶段的簇的数量都不同,对应的聚类结果也不同。只要选择其中最为合理的1个结果就好。合并簇的时候,为了找出“距离最近的两个簇”,需要先对簇之间的距离进行定义。根据定义方法不同,会有“最短距离法”“最长距离法”“中间距离法”等多种算法。
